
¡Ya puedo decir que legué hasta al final con mi master de Business Intelligence y lo he terminado!
Os cuento un poco más sobre el máster y el proyecto que he elaborado y que ya por fin he podido defender y superar, por cierto, nada de lo que escrito aquí es patrocinado, pagado o pactado con UNIR, es fruto 100% de mi experiencia desde noviembre 2020 que empecé con la aventura del máster.
Qué máster he hecho y por qué me decidí por este tema
Bueno, empezando por el principio, me decidí a estudiar un máster oficial por si acaso algún día encuentro el momento y el tiempo para hacer una tesis doctoral, por lo que en cuanto vi que existía un máster de Inteligencia de Negocio oficial y con aplicaciones reales a aprendizaje automático no me pude resistir. No es un máster tan técnico como puede ser uno de Data Science profundo, pero precisamente para un perfil menos técnico como el mío, el enfoque híbrido me ha permitido ir de menos a más, con una parte técnica y otra más de negocio o estrategia para dar contexto. Si os fijáis en el plan de estudios ya deja ver el proceso y metodología de los proyectos basados en datos, además de introducirte en fundamentos tecnológicos como son SQL y R, ¡palabras mágicas para mi!
Elegí la universidad UNIR porque ya había finalizado ahí mi Grado en ADE y para alguien que está metida en tantas cosas y tiene el tiempo justo, pues la plataforma y el enfoque 100% digital, era justo lo que yo necesitaba. En paralelo, he utilizado DataCamp para ir avanzando en temas de PowerBi, R, SQL, y también Sheets, una suscripción anual que, junto con Screaming Frog, constituye la inversión que más puedo sacar partido a día de hoy.
Estoy contenta con la experiencia, aunque ninguna formación es perfecta y en esta también han existido cosas mejorables, en general considero que he aprendido mucho y he podido rentabilizar la inversión de pagar el máster y dedicarle mi escaso tiempo, tengo un primer retorno muy valioso para mi: ahora tengo la capacidad de automatizar muchos análisis SEO con R, por ejemplo.
Como se diría en términos futbolísticos, “abrir la lata”, con el máster he descubierto una nueva disciplina que me encanta y puedo analizar mejor los datos desde prismas más estratégicos y metodológicos, así que a partir de ahora ya puedo continuar mi camino ampliando áreas o haciendo foco en lo que más me aporta, como puede ser buscar vías de análisis e implementación de modelos aplicables a SEO, ecommerce o cualquier área digital en la que ya trabajo en la actualidad.
El TFM: qué hice, por qué y para qué puede servir
Llegó enero y había que elegir tema, cuando aún estábamos asimilando conceptos y aprendiendo diferencias entre aprendizaje supervisado y no supervisado, ¿pero cómo voy a saber yo de qué hacer el trabajo? Y aunque pudimos ver trabajos de años anteriores tocó lanzarse a la piscina. Y entre ideas en mi mente y algo de research por Google, empecé a divagar sobre qué tema elegir para hacerlo:
- Predecir la conversión en ecommerce
- Mejorar el rendimiento de campañas de Adwords
- Identificar el impacto de recomendaciones SEO
- Análisis de cestas de la compra para hacer reglas de asociación y vender más
- Predecir qué palabras darán más revenue si se posicionan en primera posición
Pero la cosa no iba así, primero había que ver qué datos podía conseguir y después ver qué posibilidades me daban dichos datos para analizar y modelizar. Así que dada mi cercanía con proyectos de ecommerce, finalmente me decanté por hacerlo con algo relacionado a ecommerce, en el inicio el trabajo se llamaba Análisis Predictivo y Prescriptivo de conversión en Ecommerce y mi intención era trabajar modelos de regresión para ver si se podía predecir la conversión de varias formas e impactos.
La realidad es que de origen no contaba con los datos apropiados para lo que quería hacer y dándole vueltas a esto pude pivotar la idea hacia Métodos de Aprendizaje Automático para la mejora estratégica de las ventas online, dedicando el 80% del trabajo a técnicas de clustering de clientes y el resto, a técnicas de regresión para predecir una variable binaria Compra o No compra.
La gracia de los TFM es que en muchos casos se plantean desde un espectro académico y de investigación, lo cual metodológicamente hablando es genial y puede ayudar mucho al sector del estudio, con hallazgos, descubrimientos o justificaciones de mucho valor. En mi caso, me lancé al barro para tratar de armar un trabajo que tuviera una aplicación tangible y práctica en negocios reales, que si un ecommerce genera los datos o tiene ya una infraetructura, pueda usar modelos de machine learning que le permitan mejorar sus ventas, optimizarlas o al menos orientar sus campañas de marketing a los segmentos adecuados, lo cual ya es una priorización que le ahorra tiempos y costes.
Y ahí es donde me he enfocado, que a pesar de tener mejores o peores datos, después de este trabajo esas empresas podrían lanzar campañas para testar los modelos propuestos y sería nada costoso de hacer y de ver si tiene impacto en el negocio: por ejemplo enviando un mail a la base de datos segmentada por ciertas características.
Modelos utilizados y algunos resultados del TFM
Vamos a la chicha, ¿qué modelos he utilizado?
Después de dar muchas vueltas con los datos, finalmente pude hacerme con 2 bases de datos, limpiar datos, fusionar con otras fuentes y construir variables a partir de las iniciales. Esto es lo que aborda el trabajo:
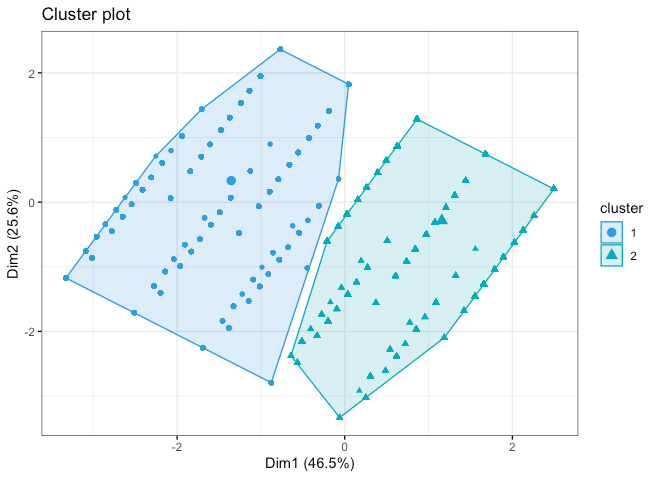
- Realizar un modelo de clusterización mediante Disimilitud de Gower, con datos de Prestashop de Clientes y de Pedidos, de cara a obtener el número de clústeres óptimos y poder analizar las características de cada uno. Este modelo se realiza con la BBDD1. Después de lanzar el modelo los clústeres óptimos se visualizan así:
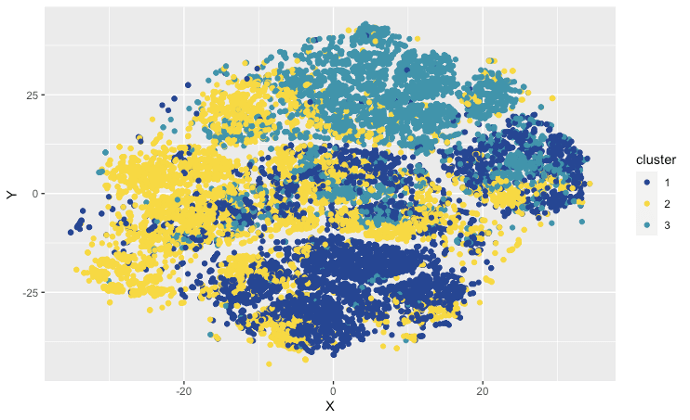
Si se aterrizan esos clústeres a una comparación de características del dataset, pues se podrían probar segmentaciones de campañas para testar si el modelo está en lo cierto o no, en este caso concreto la variable género es mayoritariamente masculina, por lo que es una característica que no servirá para segmentar.
Si queréis saber más sobre clustering y particularmente sobre el modelo de disimilitud de Gower, podéis leer más aquí
- Realizar un análisis RFM (recency, frequency, monetary), con datos de Prestashop de Pedidos, de cara a definir segmentos predefinidos de negocio, como mejores clientes, clientes perdidos, clientes fieles potenciales, etc. Este modelo se realiza con la BBDD1. Después de lanzar el modelo los clústeres estáticos se visualizan así:
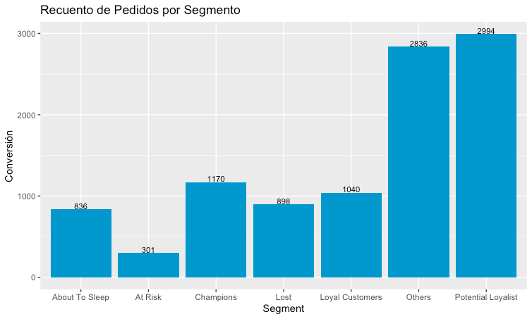
Si queréis saber más sobre los análisis RFM y su gran valía para la segmentación, podéis leer más aquí.
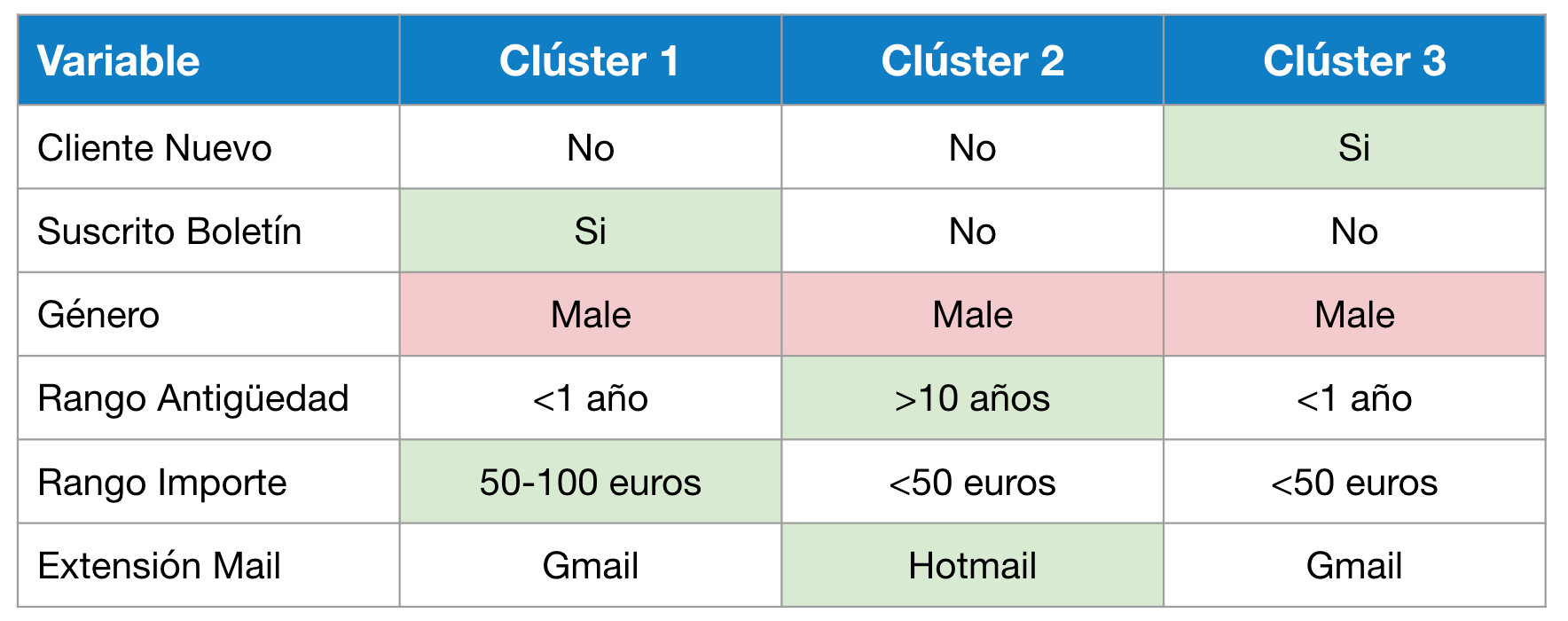
- Realizar un modelo de RFM con el mismo punto de partida que el anterior, pero con segmentación basada en el modelo K-Means para valorar los resultados en comparación con los anteriores métodos. Este modelo se realiza con la BBDD1. Después de lanzar el modelo kmeans sobre los datos, los clústeres óptimos son 2 y se visualizan así:
Si se aterrizan esos clústeres a una comparación de características del dataset, pues se podrían probar segmentaciones de campañas para testar si el modelo está en lo cierto o no, en este caso concreto la variable género es mayoritariamente masculina, por lo que es una característica que no servirá para segmentar.
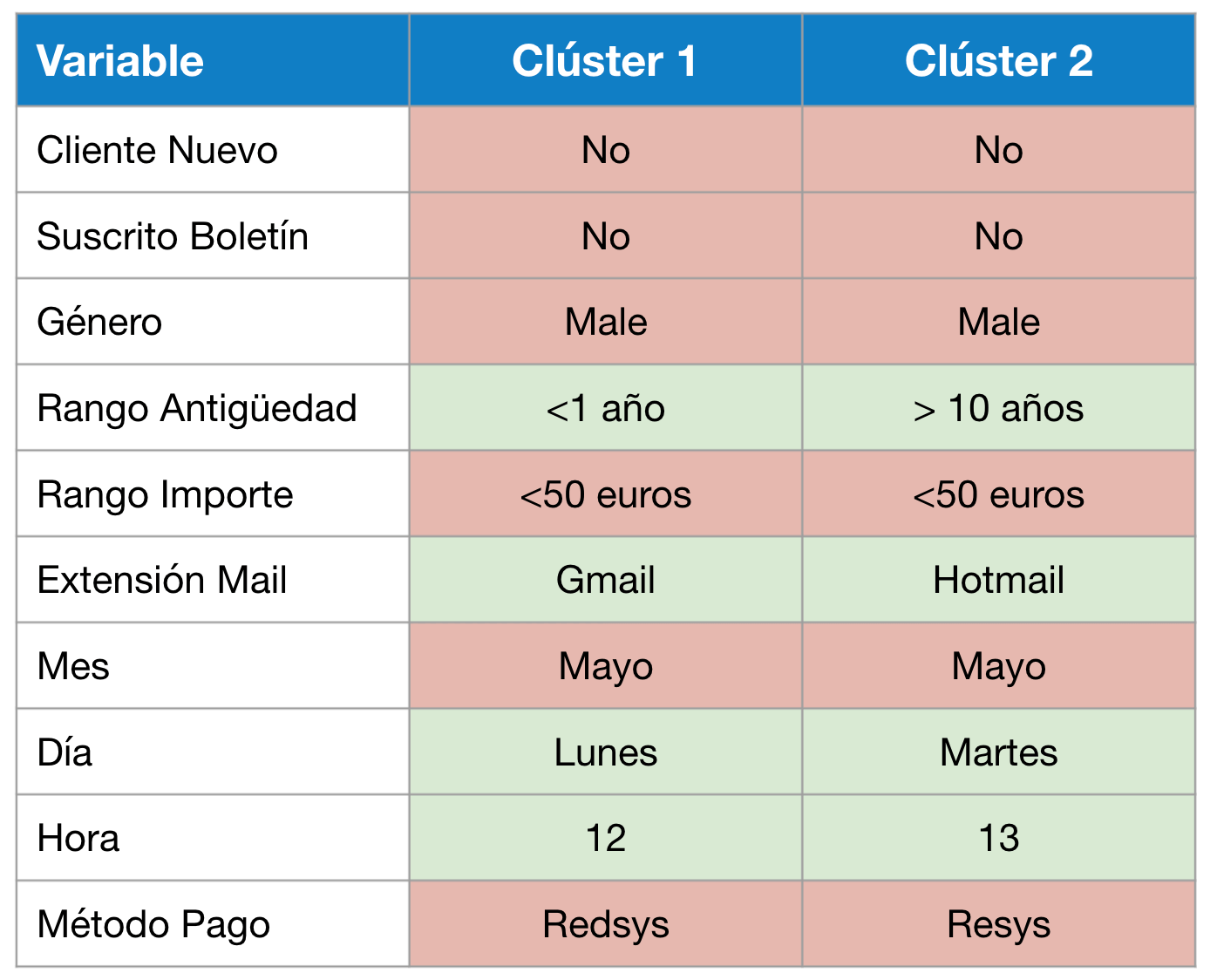
Si queréis saber más sobre RFM con k-means, podéis leer más aquí
- Realizar un modelo de regresión logística para estudiar el grado de afectación en las ventas, de los distintos factores o atributos. Este modelo se realiza con la BBDD2. Después de lanzar el modelo y hacer una predicción individual, el modelo nos puede decir la probabilidad de compra de un conjunto de características asociadas a una sesión (cliente nuevo, dispositivo, canal, método de pago)

En el ejemplo: “Los usuarios nuevos que han accedido a la tienda a través de un anuncio de Google Ads, con el dispositivo Tablet, y que han elegido el método de pago Contra Reembolso, tienen un 66,10% de probabilidades de finalizar la compra.”
Si quieres saber más sobre regresión logística podéis leer más aquí
Limitaciones de los datos, siguientes pasos y aprendizajes
Las principales limitaciones que he encontrado hacen referencia a la implementación actual de las infraestructuras en las empresas en cuanto a datos que vienen de ecommerce, analitica y crm. Sin duda que el primer stopper es no estar volcando los datos de analítica a una base de datos (tipo BigQuery), así como la trazabilidad con el CMS instalado. Además de eso, nutrir los datos de clientes lo máximo posible para tener más variables de análisis que aporten mayor valor, por ejemplo, nivel de renta, área de actividad, etc.
Lo ideal es contar con una vinculación entre los tres entornos y que el acceso de datos pueda ser automatizado o vía API, por pedir que no quede :)
El TFM entero para leer
Si has llegado hasta aquí y aún te quedan ganas de leer, he publicado el trabajo en SlideShare y se puede leer aquí mismo
Referencias principales
- chaudhury, j. (20 de Julio de 2020). Linear Regression on Ecommerce Customer Dataset. Obtenido de medium.com: https://medium.com/@jayramchaudhury20/linear-regression-on-ecommerce-customer-dataset-752bce43e0de
- Flat 101. (12 de Diciembre de 2019). flat101.es. Obtenido de flat101.es: https://www.flat101.es/estudio-sobre-la-conversion-en-negocios-digitales-espanoles-2019/
- Gaggin, A. (s.f.). Applying machine learning to sales prediction . Obtenido de rstudio: https://rstudio-pubs-static.s3.amazonaws.com/105869_f6e7f8d4e0434c40bd939a3d1e792af9.html
- IAB SPAIN. (15 de Julio de 2020). PRESENTACIÓN ONLINE DEL ESTUDIO ANUAL DE ECOMMERCE 2020. Obtenido de iabspain.es: https://iabspain.es/presentacion-online-del-estudio-anual-de-ecommerce-2020/
- Kassambara, A. (2 de Junio de 2020). K-MEANS CLUSTERING VISUALIZATION IN R: STEP BY STEP GUIDE. Obtenido de datanovia.com: https://www.datanovia.com/en/blog/k-means-clustering-visualization-in-r-step-by-step-guide/
- Khandelwal, R. (3 de Enero de 2021). Customer Segmentation in Online Retail. Obtenido de towardsdatascience.com: https://towardsdatascience.com/customer-segmentation-in-online-retail-1fc707a6f9e6
- Mishra, P. (10 de Mayo de 2019). A Practical Introduction to Prescriptive Analytics (with Case Study in R). Obtenido de analyticsvidhya.com: https://www.analyticsvidhya.com/blog/2019/05/practical-introduction-prescriptive-analytics/
- Papageorgiou, A. (20 de Febrero de 2018). The 5 Steps to Get Google Analytics Ready for Data Scienc. Obtenido de linkedin.com: https://www.linkedin.com/pulse/5-steps-get-google-analytics-ready-data-science-papageorgiou/
- Peter Bruce, A. B. (s.f.). Chapter 4. Regression and Prediction . Obtenido de oreilly.com: https://www.oreilly.com/library/view/practical-statistics-for/9781491952955/ch04.html
- pufferr. (21 de Octubre de 2019). A Machine Learning study of Google Analytics Metrics that predict Content Quality for ranking purposes. Obtenido de pufferr.co.uk: https://pufferr.co.uk/a-machine-learning-study-of-the-google-analytics-metrics-predicting-content-quality/
- Rois, S. (22 de Diciembre de 2020). Pequeña (gran) historia del eCommerce en España. Obtenido de marketing4ecommerce: https://marketing4ecommerce.net/historia-del-ecommerce-en-espana/
Soy MJ Cachón
Consultora SEO desde 2008, directora de la agencia SEO Laika. Volcada en unir el análisis de datos y el SEO estratégico, con business intelligence usando R, Screaming Frog, SISTRIX, Sitebulb y otras fuentes de datos. Mi filosofía: aprender y compartir.