

En esta guía de Screaming Frog se explican todas las opciones y casos de uso que pueden llevarse a cabo con la herramienta como auditorías seo, análisis de seo internacional, seguimiento de migraciones, auditoría de contenidos y otras funcionalidades interesantes que te permitirán buscar o extraer elementos del html. Toma asiento y ¡a por ello!
Table of Contents
INTRODUCCIÓN
Screaming Frog SEO Spider es un software creado y desarrollado por Screaming Frog, agencia de Search Marketing ubicada en Oxforshire (UK).
Este software es un crawler cuyo principal objetivo es ofrecer análisis de páginas web, desde un punto de vista eminentemente SEO.
Más información en https://www.screamingfrog.co.uk/our-story/
Esta guía hace referencia a la última versión disponible de Screaming Frog, la versión 20, lanzada en mayo de 2024 y la estoy creando después de llevar usando la herramienta desde su lanzamiento en 2010, una larga travesía que me ha llevado a dedicar miles de horas a usarla y también a formar gente para optimizar su uso.
Espero que esta guía te pueda ayudar, a ti lector o lectora, a lograr nuevos enfoques, nuevas vías de análisis o simplemente a refrescar conocimientos que quizás no sabías que tenías :)
QUÉ ES SCREAMING FROG
Screaming Frog es un programa que simula el comportamiento de un crawler, es decir, inspecciona páginas web de manera sistemática y recoge información relevante en cada rastreo, útil para su posterior análisis.
El crawler funciona como cualquier otro bot o araña, rastreando los contenidos saltando de enlace en enlace y recabando los distintos tipologías de contenidos, su extensión, su formato, su status actual y una interminable lista de ítems de gran utilidad para el diagnóstico SEO.
De este modo, la herramienta pone a nuestra disposición una serie de configuraciones con las que personalizar cada rastreo, y una vez finaliza de rastrear, ofrece distintas opciones de extracción de datos y la descarga de reports.
Este programa se descarga en entorno local (PC, Mac o Linux) y al ejecutarlo recorre el sitio web seleccionado insitu, a demanda, previa configuración de los criterios clave que se quieren comprobar, sin embargo, los resultados se pueden ir obteniendo en real time, a medida que va recorriendo la web elegida.
Este crawler SEO se convierte en una herramienta fundamental e indispensable en el día a día de un proyecto SEO, ya que permite hacer análisis profundos y concisos de la mayor parte de aspectos que intervienen en este tipo de optimizaciones:
- SEO on page: etiquetas como titles, descriptions, h1 y estructura de urls, son algunos de los elementos que permite analizar Screaming Frog
- Rastreo e indexación: etiquetas como meta canonical, meta robots, revisión de fichero robots.txt, análisis y creación de sitemaps, detección del enlazado interno, son algunos de los elementos clave en áreas de rastreo de indexación, que Screaming Frog nos permitirá estudiar.
Por otro lado, no solo podremos estudiar y analizar sitios propios, de cara a detectar anomalías o carencias para su posterior optimización, también nos posibilita hacer estudios de competencia personalizados y, en función de la licencia, sin límites.
Por último, las integraciones con Google Analytics, Google Search Console, Majestic, Ahrefs y Moz que ha logrado en sus últimas versiones, la elevan como una herramienta “must” en el arsenal de herramientas SEO, ya que vincula la parte más técnica con la vertiente de negocio, a través de datos de visitas, popularidad, autoridad y conversión.
PARA QUÉ SIRVE SCREAMING FROG
Screaming Frog Spider SEO es una herramienta que tiene múltiples usos, pero los más conocidos y extendidos, en el análisis o crawleo de un sitio web son:
- Encontrar urls rotas
- Analizar títulos y descripciones
- Auditar redirecciones
- Descubrir contenido duplicado
- Analizar o generar Sitemaps
- Revisar instrucciones y directivas robots
- Web Scraping o extracción de elementos de una web (con xpath, regex o css path)
- Analizar enlazados internos y externos
- Hacer inventario de contenidos
- Hacer o revisar el etiquetado internacional
Así, podríamos realizar análisis de impacto directo en un proyecto SEO, a nivel táctico y estratégico:
- Redirecciones en migraciones
- Etiquetado SEO internacional
- Etiquetado SEO mobile
- Elementos de SEO On Page
- Estructura y Arquitectura Web
- Estructura de Enlazado Interno
- Elementos de rastreabilidad e indexabilidad
- Elementos de Rendimiento
- Elementos de estrategia de contenidos
- Elementos y marcados semánticos
A QUIÉN VA DIRIGIDO
“La rana”, como familiarmente la llaman algunos, es una herramienta que ha conseguido democratizar el acceso a herramientas SEO a muchos profesionales, consultores autónomos, agencias, pymes…
Sin duda, va dirigido a perfiles muy diversos:
- Profesionales SEO de distintos nivel, que podrán usar la herramienta para optimziar sus sitios, analizar carencias y detectar oportunidades también analizando competidores.
- Desarrolladores web que podrán revisar y comprobar sus modiicaciones en entornos locales o privados, antes de aplicar los cambios en las webs en vivo.
- Propietarios de páginas webs que podrán identificar y diagnosticar las problemáticas técnicas y de contenido de su sitio.
- Departamentos de contenidos que podrán trabajar en optimizar sus contenidos, analizando el estado de las principales métricas.
- Equipos de diseño y UX que participen en lanzamientos, podrán chequear el estado del sitio a nivel de diseño en distintas resolucione, así como revisar copies y contenidos de cada página.
LICENCIAS Y PRECIOS
La herramienta la podemos comenzar a utilizar sin necesidad de tener una licencia de pago, desde aplicaciones ya podemos abrir Screaming Frog y realizar algún rastreo.
No obstante, es necesario conocer los límites de no contar con una licencia, para no llevarnos sorpresas, con la versión Free, solo podrás:
- Crawlear como máximo 500 urls
- Acceso restringido a las opciones de configuración
- No podrás guardar los crawleos que hagas
- No podrás usar la funcionalidad de conectar Google Analytics
- No podrás usar las funcionalidades de extracción para scrapear, o la de buscar código en el crawleo
El precio de Screaming Frog es de 239 euros por usuario al año y se puede contratar en https://www.screamingfrog.co.uk/seo-spider/licence/
En resumen, puedes acceder a Screaming Frog gratis para usos de 500 urls o menos (sin posibilidad de configurar nada) y por otro lado, la licencia de pago de Screaming Frog te permite usar libre e ilimitadamente la herramienta para todos los usos y configuraciones que desees.
INSTALACIÓN
Para instalar el software de Screaming Frog en entornos Apple, se requiere disponer de Java 7 y al menos 512Mb de RAM y lo primero que tendremos que hacer es descargar el archivo ejecutable, disponible en la web de Screaming Frog, en la sección Downloads o Descargas.
Puedes descargar la herramienta en los siguientes sistemas operativos:
- Windows
- Mac (Intel o Apple Silicon)
- Linux (Ubuntu o Fedora)
Consigue la que más se adecúe a tus intereses en este link: http://www.screamingfrog.co.uk/seo-spider/#download
INTRODUCCIÓN VISUAL A LA INTERFAZ
Visualmente, Screaming Frog es sencillo de usar, después de una primera comprensión de las distintas zonas que existen en el software, que son 4:
- Menú horizontal o cinta de opciones: abrir y guardar archivos, cambiar el modo de crawleo, varias opciones de exportar reports, generar sitemaps, etc.
- Zona o panel central (azul): donde tendremos todas las métricas de análisis y los datos del proyecto que crawleemos.
- Zona o panel inferior (verde): aquí se mostrará información específica de los datos que seleccionemos en el panel central, de forma individual
- Zona o panel lateral (naranja): en esta zona se encuentra información agrupada a modo de resumen y opciones de arquitectura, tiempos de respuesta y gráficos en la zona inferior.
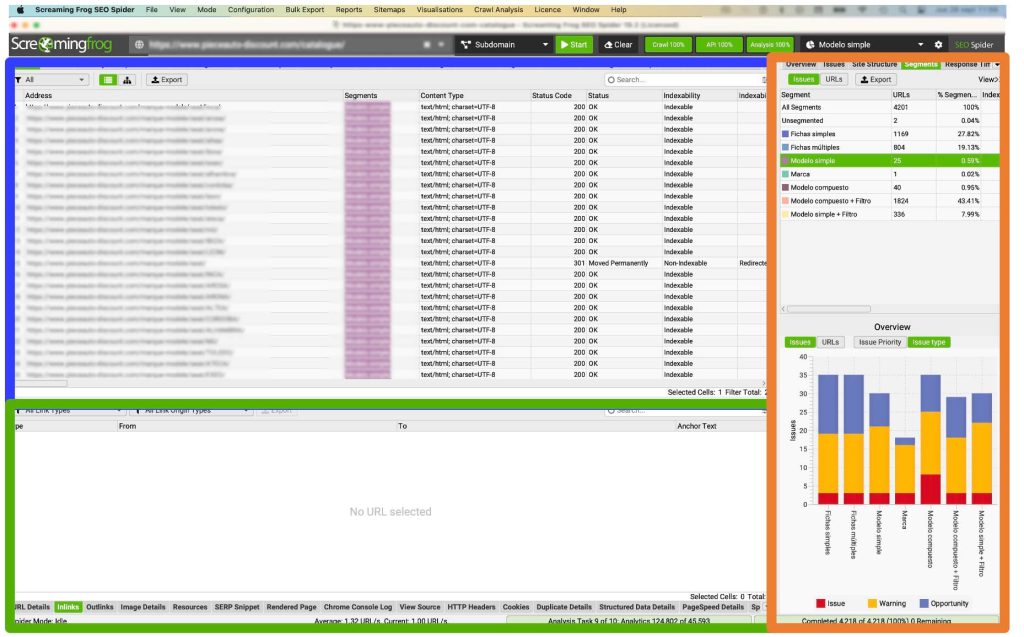
MENÚ DE OPCIONES
SECCIÓN SCREAMING FROG
Empezando por la cinta de opciones, vamos a profundizar en qué posibilidad ofrece Screaming Frog en cada una de ellas, concretamente en la primera “Screaming Frog”.
Por mantener la cohesión durante la guía, las opciones se explican en español y se añade el idioma por defecto de la herramienta (el inglés) entre paréntesis, si usas Screaming Frog en otro idioma la ubicación de los elementos es la misma y no debería generarte demasiada problemática (además que la heramienta ha estado 100% en inglés más de 10 años)
Vamos a por las opciones :)
ACERCA (ABOUT)
Screaming Frog, em un ejercicio de transparencia, explica y detalla todos los proyectos de código abierto que utiliza para desarrollar el software:
- ph-css
- jsoup
- MinHash Library
- ANTLR v4
- Gson
- Roboto
- JSONLD-Java
- dat.gui
- google/robotstxt
- The Guava project
- TopBraid SHACL API
- 3d-force-graph
- TwelveMonkeys ImageIO
- LanguageTool
- Java Diff Utils
- opencsv
- Apache Software Foundation
- HtmlCleane
- Chrome DevTools Java Client
- JavaFX
CONFIGURACIONES (SETTINGS)
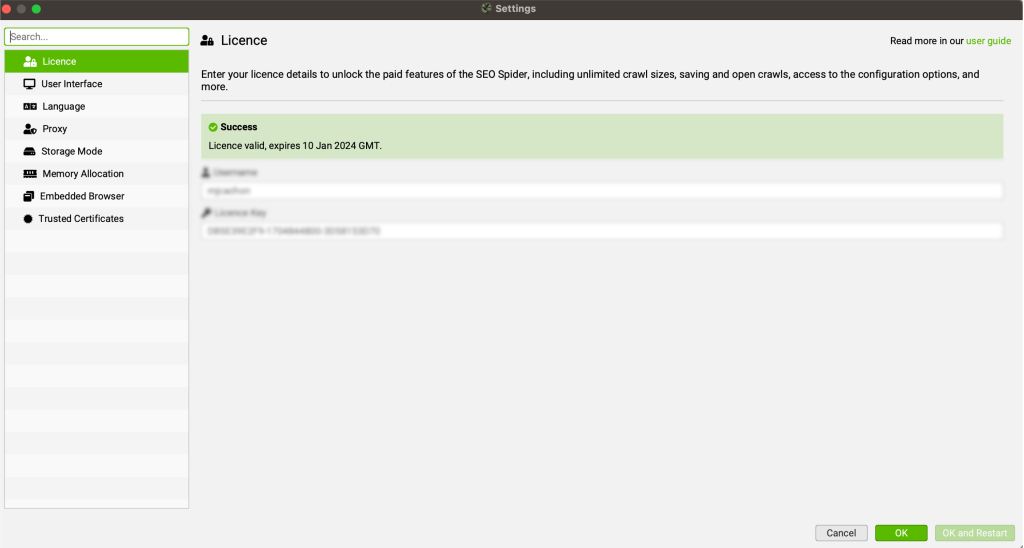
LICENCIA (LICENSE)
Este es el lugar donde se añaden los datos de la licencia una vez la has adquirido que constan de username y de license key.La licencia es anual por lo que aquí también se podrá ver desde esta sección la fecha en la que caduca. Usualmente una vez se renueva, se añaden los nuevos datos aquí y se reinicia para que tengan efecto.
INTERFAZ DE USUARUO (USER INTERFACE)
Tienes varias opciones para personalizar la interfaz. Por un lado el theme puede ser modo claro o modo usocuro. ADemás de eso tienes ahora una paleta de colores extensa para modificar el color de la interfaz y personalizarlo a tu gusto.
Por otro lado, se ha añadido el «Focus mode» que si lo activas lo que ocurrirá es que se ocultarán automáticamente las pestañas que no se utilizan para reducir el desorden y ayudarte a centrar tu atención en lo estrictamente necesario.
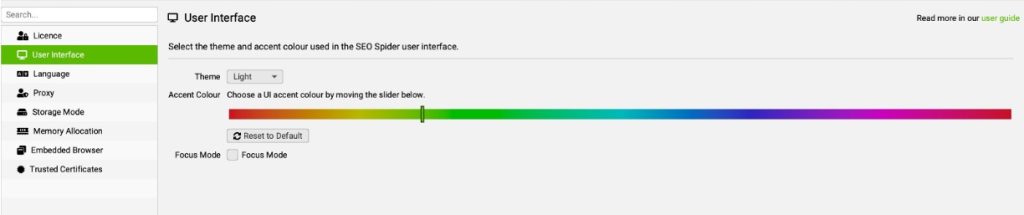
Respecto al theme en si, los modos los podrías visualizar como se ve en la imagen, si te viene mejor más o menos contraste, elige a conciencia
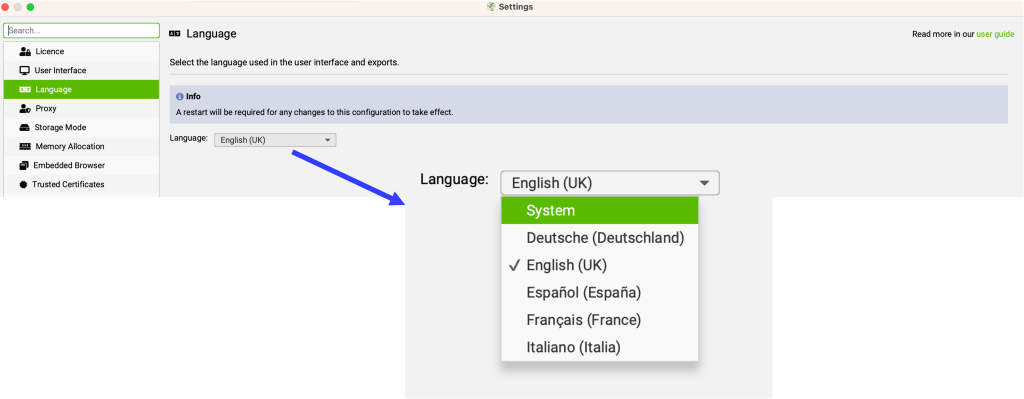
IDIOMA (LANGUAGE)
Respecto al idioma puedes dejar el que tienes en tu sistema configurado o elegir de la lista el que mejor se adecúe a tus necesidades. Un consejo por experiencia, si has pasado mucho tiempo usando la herramienta en inglés y luego te pasas a usarla en español, quizás tienes ciertas dificultades los primeros días porque «no encuentras» las cosas tan rápido como antes, al cambiar sustancialmente los nombres de los campos :)
MODO DE ALMACENAMIENTO (STORAGE MODE)
El modo de almacenamiento marca bastante la experiencia de uso en Screaming Frog, ya que si usas el modo Memoria, todos los rastreos que hagas irán contra la memoria de tu ordenador y eso implicará que cada vez que un crawleo termine, tendrás que guardar el fichero resultante (igual que si guardas un fichero de excel) y ese fichero se guarda en tu equipo.
De otro modo, podrías elegir el modo Base de Datos, que es una forma de auto-guardar los rastreos automáticamente, puesto que asociarías el almacenamiento a una unidad que tu indiques (lo recomendable es un SSD).
La segunda opción es más beneficiosa porque también permitrá que puedas usar funcionalidades adicionales como puede ser el Modo Comparar que veremos más adelante.
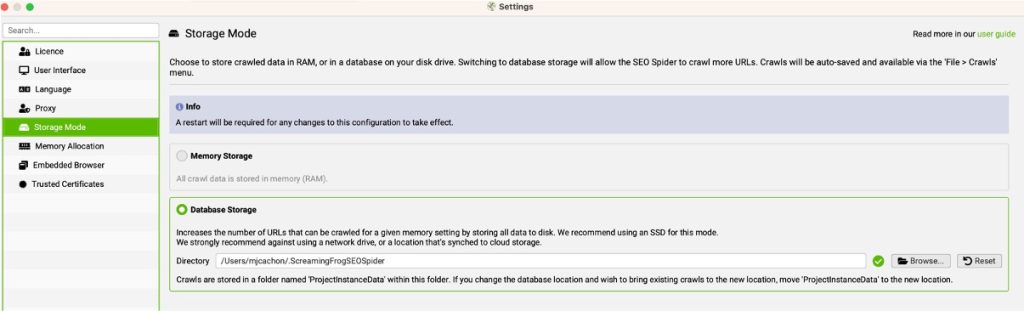
Si eliges Almacenamiento Memoria, verás este menú:
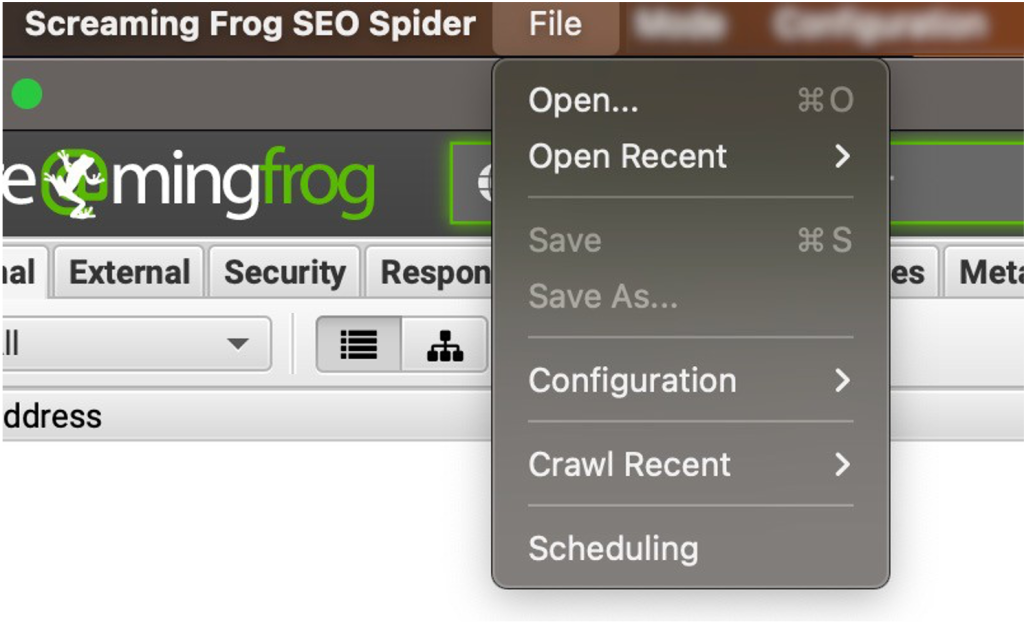
Si eliges Almacenamiento Base de Datos, verás este menú:
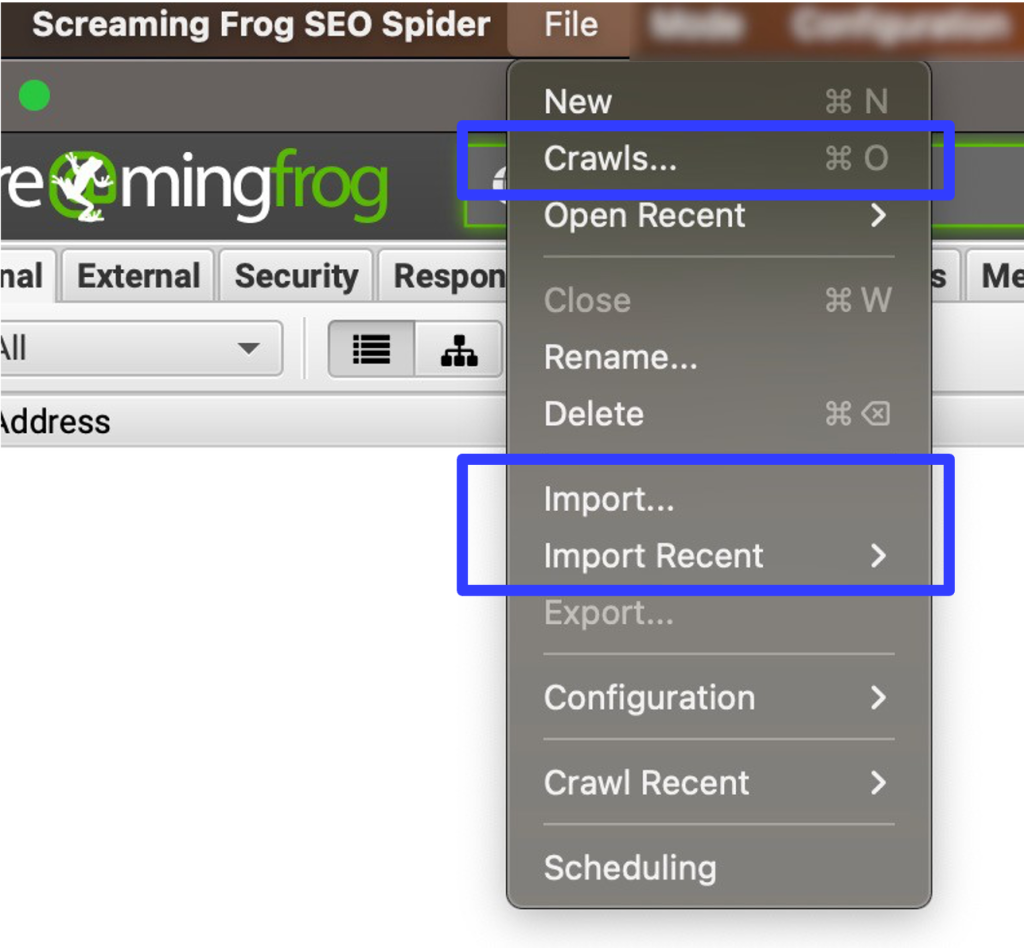
Y cuando accedas a»Crawls» verás dónde se guardan todos los rastreos que hagas y podrás renombrarlos, hacer carpetas, etc.
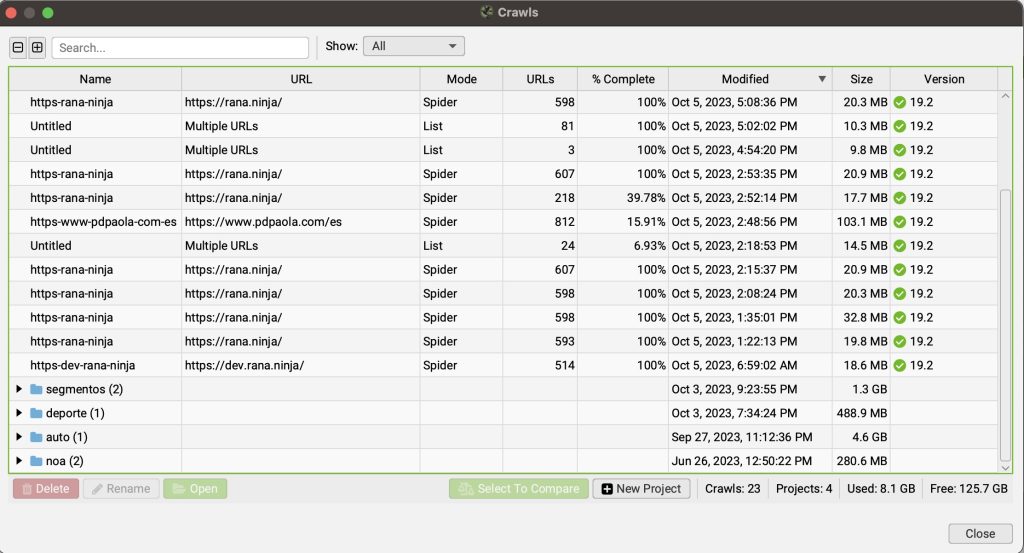
ASIGNACIÓN DE MEMORIA (MEMORY ALLOCATION)
En esta configuración se puede asignar la memoria RAM que se quiere asignar a Screaming Frog.
En cualquier caso, todo dependerá de la capacidad de tu equipo y de si lo usas solo para Screaming Frog o para más tareas.
El software te recomendará que dejes un margen de al menos 2 GB de memoria para el resto de funciones que requieras.
Aumentar la asignación de memoria hará que la herramienta rastree más URLs, particularmente en cualquier modo de almacenamiento.
SECCIÓN ARCHIVO (FILE)
En esta sección se pueden encontrar opciones relativas a abrir ficheros, guardar ficheros y jugar con las opciones por defecto, o la de guardado de configuraciones, algo tremendamente útil si tenemos casuísticas que se repiten con frecuencia. Por ejemplo, si solemos rastrear un sitio periódicamente es probable que necesitemos guardar las opciones de configuración para agilizar la tarea y cada vez que tengamos que rastrear el sitio, no perder tiempo en configurarlo a mano, cuando siempre o casi siempre, la configuración será la misma.
OPCIONES PARA ABRIR FICHEROS
ABRIR (OPEN)
Esta opción solo estará disponible para configuración de almacenamiento Memoria.
Con la opción Open, tal y como su nombre indica, vamos a poder abrir archivos de Screaming Frog que tuviéramos guardados previamente en nuestro equipo.
Su funcionamiento es simple, clicamos y elegimos qué archivo queremos abrir.
El formato del archivo que genera Screaming Frog tiene la siguiente sintaxis y extensión:
Nombre_Fichero.seospider
Por tanto, cuando el diálogo se nos abra para elegir archivo, solo podremos elegir este formato.
ABRIR RECIENTE (OPEN RECENT)
Esta opción estará disponible para configuración de almacenamiento Memoria y Base de datos.
Cuando ya hemos utilizado el crawler, esta opción nos permitirá abrir archivos recientes, sin duda una forma rápida y ágil para recuperar los datos de los proyectos recientes. Tan solo tendremos que elegir de la lista de proyectos que aparezcan en el desplegable y seleccionar el que queremos abrir:
OPCIONES DE GUARDADO
GUARDAR (SAVE)
Esta opción solo estará disponibles para configuración de almacenamiento Memoria.
La opción Save, nos permite guardar el proyecto que hayamos terminado de crawlear, para guardar esa información. Esto es especialmente útil si hacemos crawleos periódicos a un proyecto, de cara a ir comparando versiones y viendo mejoras en elementos clave.
También es útil guardar un crawleo antes y después de una migración, para tener el status previo y poder detectar errores o anomalías.
Para guardar un crawleo, una vez este haya finalizado, elegimos donde guardamos el proyecto y le ponemos un nombre, siempre recomendable que sea lo más descriptivo posible.
RASTREO RECIENTE (CRAWL RECENT)
La opción Crawl Recent, nos permite acceder a los últimos crawleos que hemos efectuado y poder abrirlo a golpe de click.
El mayor caso de uso con esta opción es acceder rápidamente a los crawleos frecuentes o recientes, para re-configurar y volver a lanzar.
SECCIÓN VISTA (VIEW)
En este bloque podemos acceder a opciones que tienen que ver con cómo se visualizan las cosas en la interfaz y las funcionalidades o configuraciones relativas a visualizar columnas, tablas, pestañas, etc.
RESETEAR COLUMNAS (RESET COLUMNS)
Las columnas se pueden reordenar arrastrándolas y soltándolas en nuevas posiciones con el ratón. También se pueden ocultar usando el menú + tal y como se indica en la imagen .
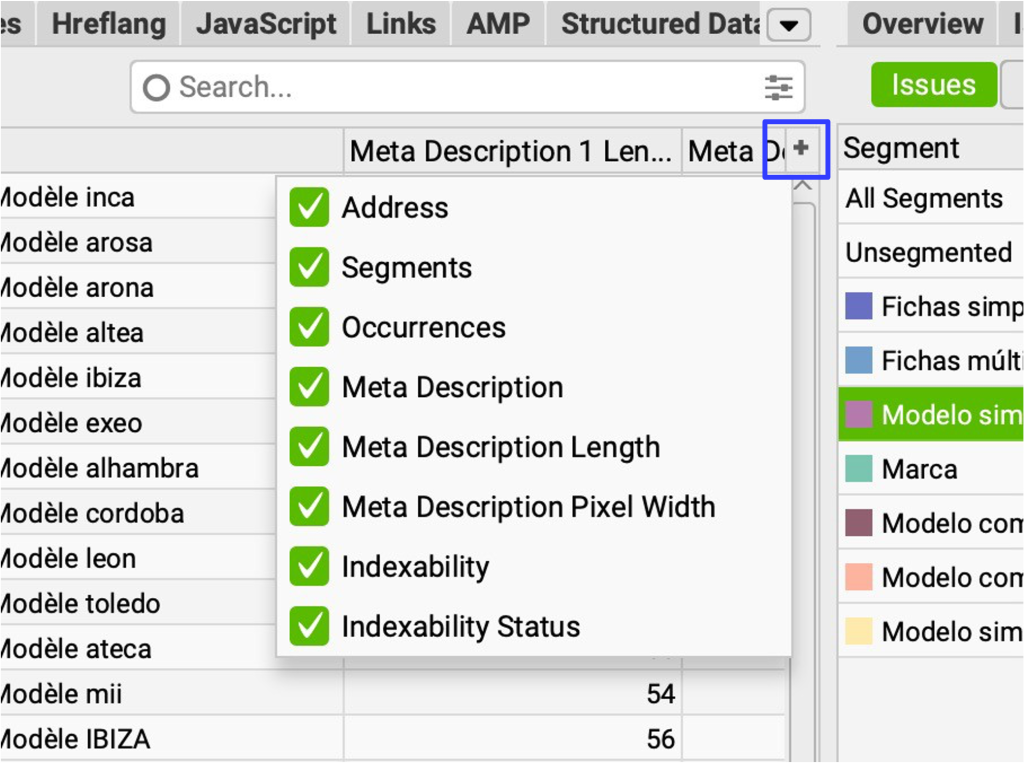
Si las has cambiado de algún modo para trabajar en algún análisis y quieres volver al estado original, puedes pinchar aquí y volverán al lugar por defecto.
La flexibilidad de Screaming Frog es tal que permite la personalización que cada persona quiera y siempre es fácil volver a dejarlo como estaba de inicio.
RESETEAR PESTAÑAS (RESET TABS)
Las pestañas se pueden reordenar arrastrándolas y soltándolas en nuevas posiciones con el ratón. Esto se aplica tanto a las pestañas del panel inferior como del panel central.
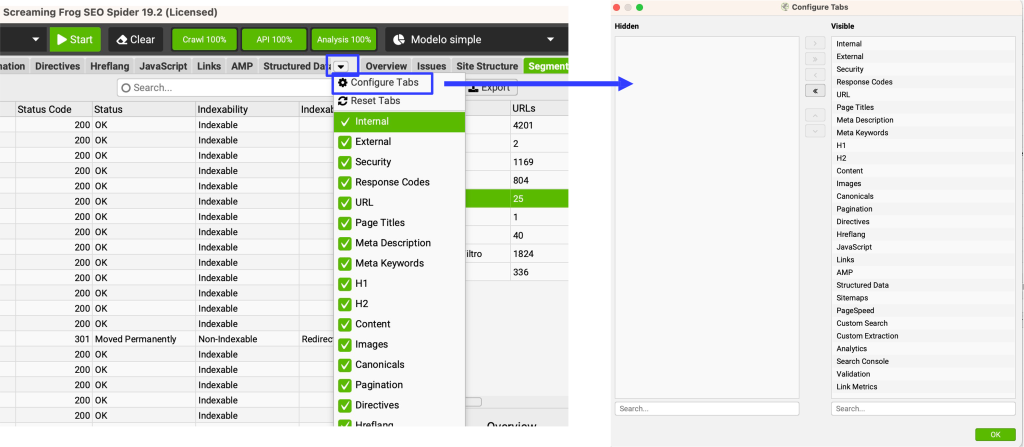
También se pueden ocultar haciendo clic derecho en cualquier pestaña y eligiendo «Cerrar».
Si las has cambiado de algún modo y quieres volver al estado original, puedes pinchar aquí y volverán al lugar por defecto.
MODO FOCUS (FOCUS MODE)
De forma predeterminada todas las pestañas se muestran en la interfaz de usuario, pero si activas el «modo de enfoque» la herramienta oculta automáticamente las pestañas que no están en uso para quitar ruido.
Por tanto, si activas el ‘modo de enfoque’ está habilitado y en un rastreo no has configurado aspectos como «Datos estructurados», «Mapas del sitio» o «Extracción personalizada», el «modo de enfoque» se encargará de ocultar todas esas pestañas.
SECCIÓN MODO (MODE)
Las formas de trabajo con Screaming Frog se resumen en modos, siendo el modo Spider el más usado, sigue siendo relevante explicar todos los modos de cara a poder exprimir la herramienta aún más. Cada modo te orientará a un tipo de análisis específico o te habilitará unos casos de uso más claros, ten lo en cuenta antes de empezar a rastrear.
ARAÑA (SPIDER)
Este es el modo predeterminado de Screaming Frog. En este modo, la herramienta rastreará un sitio web, recopilará enlaces y clasificará las URL en distintas pestañas y filtros.
Este modo habitualmente es el que usamos en el 80% de los rastreos, con la configuración apropiada respecto al objetivo del rastreo, pero es el rastreo que inferirá el enlazado interno del sitio.
Casos de uso habituales para este modo:
- Rastreos para detectar errores
- Rastreos para comprobar implementaciones
- Rastreos para detectar profundidad
- Rastreos para detectar mejoras de enlazado interno
- Rastreos para analizar contenidos
- Rastreos para identificar qué urls tienen más visitas y cruzarlas con otras métricas SEO
- Rastreos para conectar APIs de terceros como Page Speed
Los casos de uso son casi infinitos, en este modo la clave es entender qué configuración debes hacer para conseguir lograr tu objetivo de análsisi, ni más ni menos.
LISTA (LIST)
En este modo se hace un rastreo basándose en una lista predefinida de URLs. Esta lista se puede proporicionar simplemente copiando y pegando o adjuntando un archivo .txt, .xls, .xlsx, .csv o .xml.
Es importante considerar que para que la lista de urls sea válida, las urls deben contener todos sus componentes, incluyendo los prefijos de protocolo como http:// o https://.
Además, también se encarga Screaming Frog de quedarse solo con las URLs únicas, por tanto normaliza y desduplica todas las URLs al cargarlas, con esto nos ahorramos una parte del trabajo nosotros.
Si es más cómodo para ti subir un fichero que has descargado de otro sitio (por ejemplo Urls posicionadas de Google Search Console o de Sistrix), es interesante saber que Screming Frog solo se va a quedar con las urls, lo demás lo va a ignorar.
De manera predeterminada, este modo configura «ignorar robots.txt» y profundidad cero (no va a hacer clic en ningún enlace, solo rastreará la lista) así que tenlo presente si ese comporatmiento no es el que quieres para tu análsiis.
Lo que tendrás a tu disposición al habilitar el modo lista desde el botón del menú «Mode» (o Modo en español) son las siguients opciones, tal y como se muestra en la imagen, primeramente desaparece la barra de direcciones y aparece un botón de Upload, con distintas opciones.
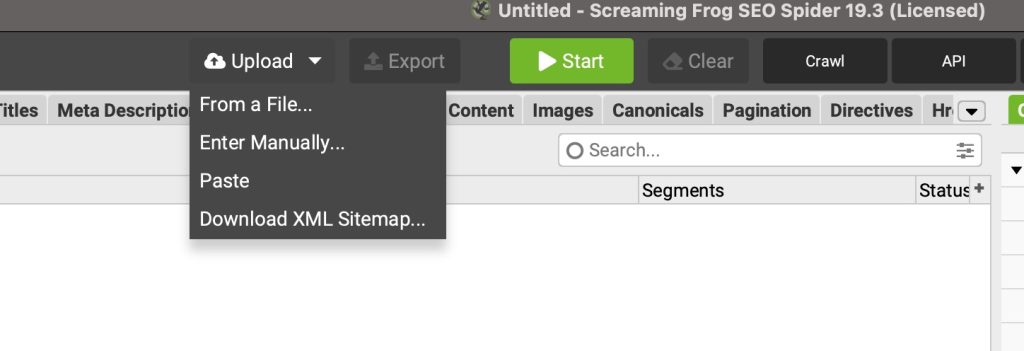
- From a file: nos permite subir un fichero .txt, .xls, .xlsx, .csv o .xml.
- Enter Manually: añades a mano las urls que quieras, recuerda que las urls deben contener todos sus componentes (el protocolo es obligatorio).
- Paste: si copiaste las urls de otro lado, puedes pegarlas aquí y Screaming Frog las reconocerá, normalizará y desduplicará.
- Download XML Sitemap: puedes añadir directamente la url de tu sitemap
Casos de uso habituales para este modo:
- Rastrear una lista de redirecciones de una migración
- Rastreo de un segmento de urls concreto
- Rastreo de una lista de urls y extraer las visitas que han tenido en un periodo de tiempo (con la API de Google Analytics 4)
- Rastreo de lista de competidores
- Rastreo de urls que nos enlazan externamente
- Rastreo de una lista de competidores de las SERPs
Nuevamente podrás observar que se recogen los casos más típicos pero esta funcionalidad te llevará donde tu imaginación SEO llegue, los casos de uso son extensos y muy personalizables para cada proyecto, sector o situación.
SERP
El modo SERP analiza títulos y descriptiones para ver cuánto ocupan de largo en caracteres y en píxeles, por tanto, si cargas un listado con esos campos se hará el cálculo en bulk o masa de la longitud de los elementos.
Dado que en este modo no hay rastreo como tal no es necesario que las etiquetas estén ativas en un sitio web, sino que la información será analizada sin consultar la web, solo analizando los elementos.
Casos de uso habituales para este modo:
- Analizar top 10 resultados de una keyword
- Analizar los elementos de un segmento concreto y ver mejoras
- Analizar metadata SEO previa a añadir a la web
COMPARAR (COMPARE)
Con este modo podrás comparar dos rastreos y ver una comparación de los datos para identificar cómo han cambiado a lo largo de las distintas pestañas y filtros.
Es muy importante saber que para poder usar este modo es necesario tener configurado el modo de almacenamiento Base de Datos, sino no podrás disfurtar de este modo.
Una vez lo tengas, cuando lo actives, podrás ver en la interfaz que desaparece la barra de direcciones y te permite elegir los dos crawleos que quieres comparar: uno se marcará como «Current» o actual y otro se marcará como «Previous» o previo. Utiliza tu criterio para indicar cuál es cuál.
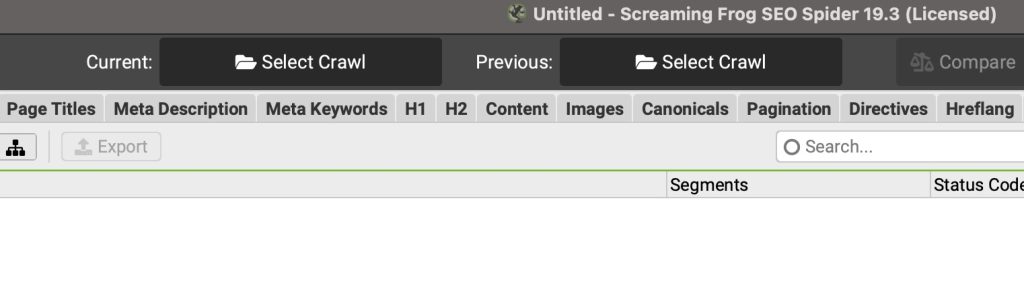
Casos de uso habituales para este modo:
- Comparar migración pre y post.
- Comparar entorno staging con entorno real.
- Comparar versión mobile con versión desktop.
- Comparar crawleo con JS y crawleo con modo texto.
SECCIÓN CONFIGURACIÓN
Sin duda esta sección de la herramienta es la más importante antes de empezar a analizar y a extraer datos de un proyecto web.
Ahora profundizaremos en el por qué y en el cómo, pero debemos tener en cuenta cuál es el objetivo que perseguimos con un crawleo o análisis, antes de pulsar en el botón “start”.
A priori, sin entrar a otras funcionalidades más concretas, vamos a poder hacer dos análisis principales:
- Análisis en bruto de un proyecto: para detectar el status actual de una web, en términos de SEO On Page, etiquetas e instrucciones para robots, extensión de los contenidos, tiempo de carga, situación del enlazado, etc.
- Emular comportamiento de un rastreador bot como puede ser Googlebot: para comprobar y comprender cómo se rastrean e indexan los contenidos del sitio web analizado.
Obviamente cada una de estas opciones, utilizará unos criterios a nivel de configuración muy distintos, para poder acotar la información resultante que obtendremos en cada caso.
RASTREO ARAÑA (SPIDER CRAWL)
El rastreador, crawler o araña, nos permite configurar los parámetros que utilizará para recorrer la url o urls que le indiquemos, en base al objetivo que persigamos.
Cabe recordar que deben configurarse estas opciones antes de empezar, de cara a obtener la información esperada. Por defecto, la herramienta vendrá con la siguiente configuración ya cargada:
Pero como se puede ver, simplemente marcando o desmarcando cada check, estaremos personalizando la configuración para cada caso.
Disponemos de 4 secciones de opciones. La primera de ellas contiene múltiples opciones que pueden configurarse de distintos modos y para fines diferentes.
Esta es una de las pestañas más importantes de la configuración, por lo que repasamos una a una todas las opciones
IMÁGENES (RESOURCE LINKS: IMAGES)
Marcando esta opción, Screaming Frog crawleará links de imágenes de la etiqueta SRC o bien enlazadas como anchor de un href.
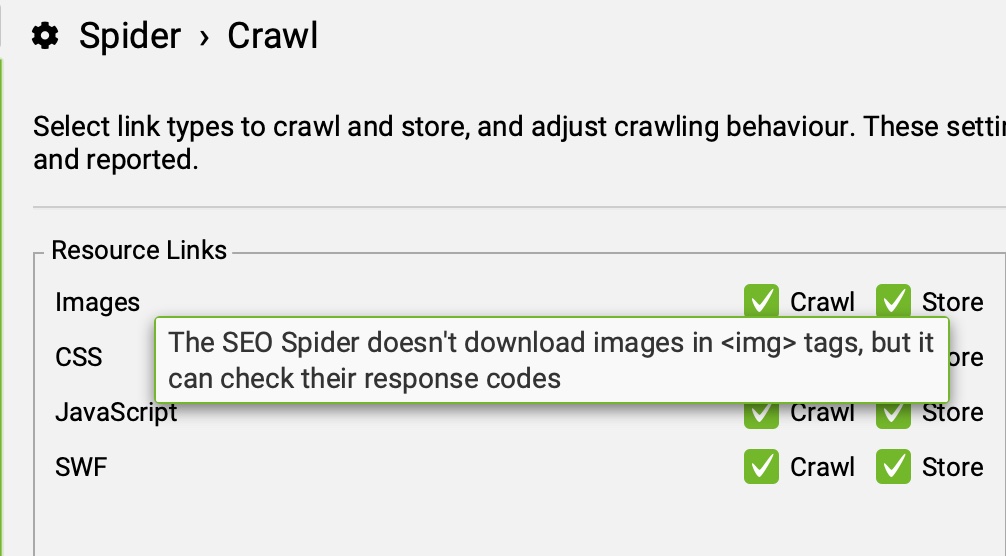
Hay una opción relacionada en la pestaña “advanced” que puede ayudar a ampliar el crawleo de imágenes y que explicaremos más adelante.
¿En qué situaciones puede ser útil usar esta opción?
La optimización de imágenes en proyectos de marketing online y SEO, pasa por varios aspectos fundamentales:
- El nombre de la imágen
- El peso de la imágen
- La etiqueta ALT de la imágen
- El texto que rodea a la imágen
Con esta opción permitiremos a Screaming Frog crawlear las imágenes y obtener los tres primeros elementos comentados, para que sirvan como punto de partida a detectar posibles mejoras y optimizaciones, destacando como principales casos de uso específicos:
- Detectar nombres de ficheros no optimizados
- Detectar imágenes que pueden pesar menos o ser comprimidas
- Detectar imágenes sin ALT o con un ALT optimizable
- Detectar imágenes rotas (que responden 404)
¿Qué es la etiqueta ALT?
El atributo o etiqueta ALT es un texto que describe el contenido de una imagen, es el Alternate Text o Texto Alternativo y definirlo correctamente es importante porque:
- Ofrecerá un contexto semántico a la imagen, explicando el contenido con palabras o frases descriptivas. Google utiliza esta información para mostrar las imágenes más relevantes el las búsquedas
- Por cuestiones de accesibilidad web, existirán usuarios que utilicen navegadores sonoros o lectores de pantalla para visitar webs y consumir los contenidos. Esta etiqueta ALT será de vital importancia de cara a la experiencia de navegación de personas que usen estos navegadores.
Por otra parte el uso excesivo de keywords en esta etiqueta puede generar experiencias negativas para los usuarios, y por parte de Google, puede llegar a considerar el sitio como spam. De manera adicional, se pueden probar los contenidos y las descripciones añadidas en la etiqueta ALT con un navegador de sólo texto como puede ser Lynx.
Dicho esto, configura esta opción si quieres hacer alguna de las cosas que ya se han mencionado, y si estos aspectos no forman parte de tu objetivo de análisis, no lo marques y ahorras recursos y tiempo en el crawleo, será más ágil y eficiente.
ARSCHIVOS CSS (RESOURCE LINKS: CSS)
Marcando esta opción, Screaming Frog crawleará links de ficheros CSS, que estén vinculados en el HTML de la web.
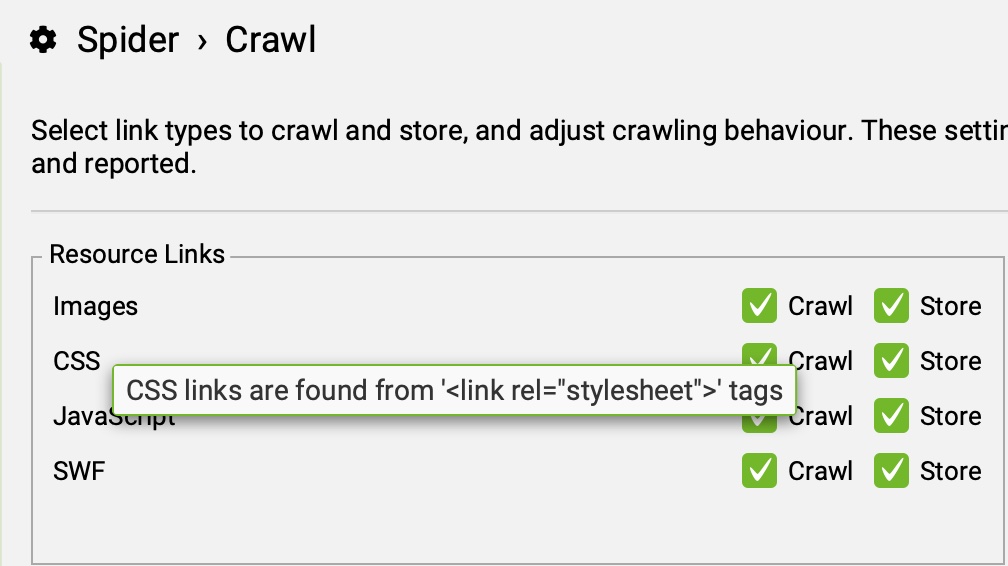
¿Qué es un fichero CSS?
CSS u hojas de estilo en cascada, es un lenguaje de hojas de estilo usado para definir y describir un documento HTML.
Así los archivos CSS son los responsables de pintar la capa visual de todas las webs que conocemos hoy en día, marcando la separación entre el contenido de un documento y la presentación, para que sea lo más accesible posible.
De esta forma, es posible presentar el mismo documento con distintos estilos, enfocados a distintos objetivos:
- Distintos renderizados
- Distintas pantallas
- Distintos navegadores (voz, pantalla, táctiles…)
- Distintos dispositivos
Las instrucciones incluidas en un fichero CSS marcan las pautas o reglas de estilo que deben aplicarse a los distintos elementos del documento, para conseguir los efectos deseados: tamaño de fuente, colores, disposición de menús, etc.
Recuerda que rastreadores como Googlebot necesitan ver este tipo de ficheros para entender el contenido en su conjunto, así que se les debe permitir el rastreo siempre. En cuanto a Screaming Frog, pues depende de cuál sea tu objetivo de análisis, podrás desactivar esto o no, a priori, no van a generar un gran consumo de recursos y no marcarán gran diferencia si lo desactivas, así que suele ser buena idea mantenerlo activado en todos os crawleos.
ARCHIVOS JS (RESOURCE LINKS: JAVASCRIPT)
Marcando esta opción, Screaming Frog crawleará links de ficheros JS, que estén vinculados en el HTML de la web. Dado que la herramienta usa los links HTML para realizar el rastreo, aquellos casos en los que existan links dentro de Javascript o la web esté construida en Javascript, será necesario usar una opción especial de renderizado que se menciona más adelante en Configuración > Spider > Rendering.
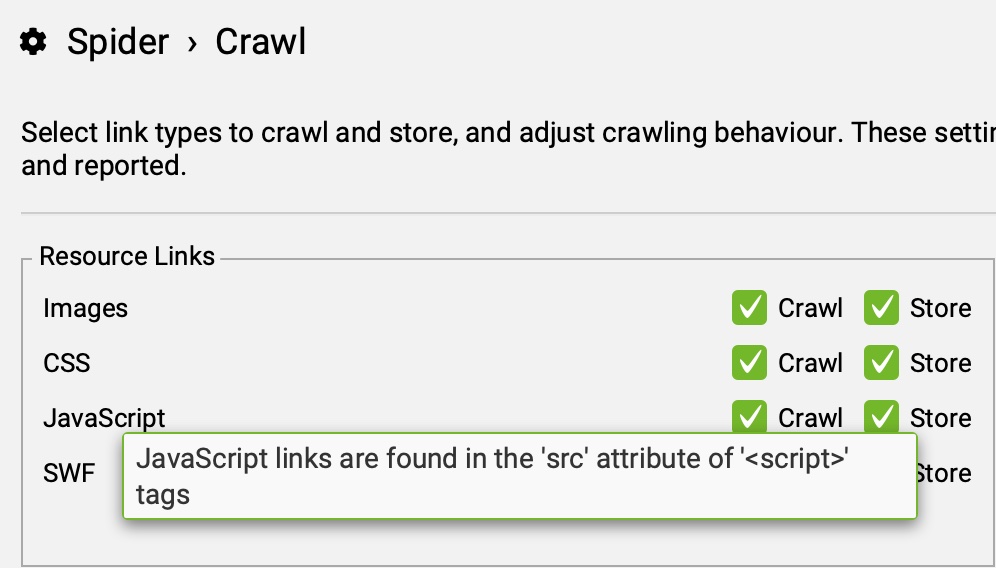
¿Qué es Javascript?
JavaScript es un lenguaje de programación del lado del cliente, es decir, se ejecuta en el cliente (por ejemplo, el navegador), en vez de en el servidor.
El código JavaScript puede crear efectos dinámicos en la web, como por ejemplo, que se despliegue un menú acordeón al pasar el ratón por encima.
Podría ser un inconveniente que, si un usuario tiene desactivado JavaScript en su navegador, no podrá ver todos los efectos o contenidos dinámicos que aporta Javascript en la web, a pesar de que la mayoría de navegadores interpretan bien dicho código.
Por lo demás, en lo que respecta a Googlebot, el rastreador principal de Google, se requiere que este tipo de archivos sean rastreables de cara a que Google pueda renderizar el contenido al completo y entenderlo en su totalidad. Tenlo en cuenta en tus proyectos y blo uses robots.txt para bloquear este tipo de archivos.
ARCHIVOS FLASH (RESOURCE LINKS: SWF)
Marcando esta opción, Screaming Frog crawleará links de archivos flash, que estén vinculados en el HTML de la web.
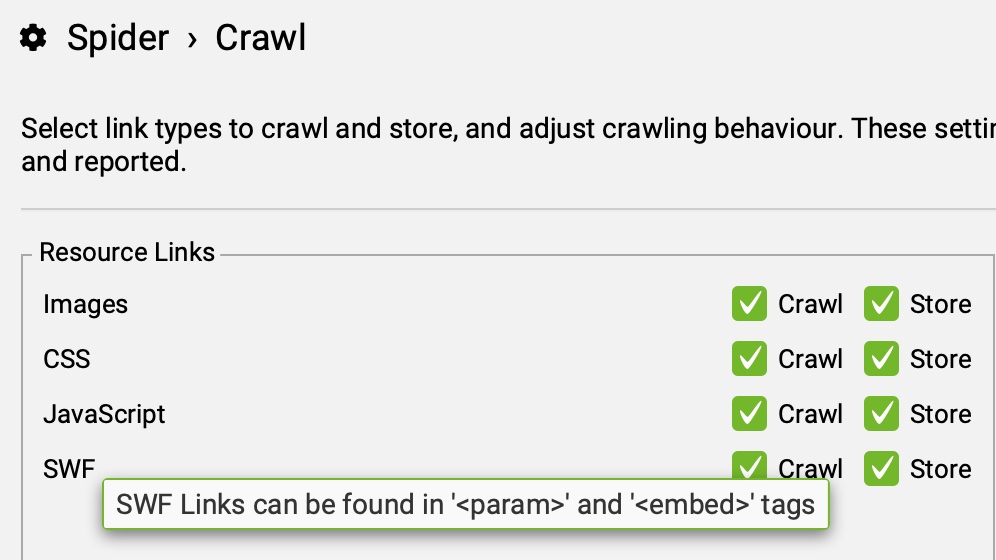
Este formato es menos habitual en la actualidad, no obstante, todo dependerá del proyecto en el que se esté trabajando, pues que sea un formato minoritario, no implica que sea inexistente.
Enlaces internos (PAGE LINKS: INTERNAL LINKS)
Marcando esta opción, Screaming Frog rastreará los enlaces internos y estarán disponibles en la interfaz de la herramienta una vez finalice el rastreo.
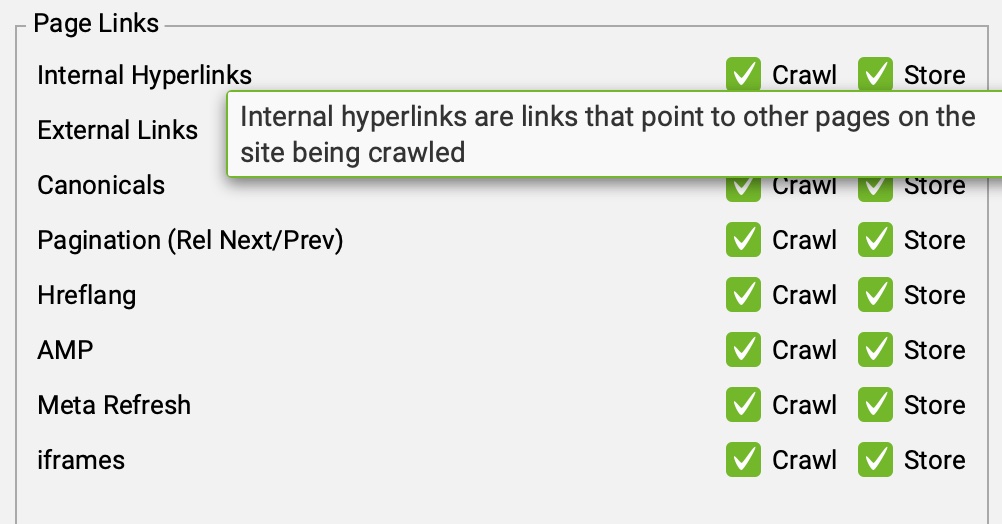
Cabe destacar que, de forma predeterminada, está opción ya viene activada para mantener este comportamiento en cualquier proyecto.
Y por ir al detalle, hablamos de enlace interno cuando son urls que pertenecen al mismo subdominio que hayamos indicado en la herramienta como punto de partida. Por otro parte, el enlace es considerado así cuando están construidos con la etiqueta <a href= de HTML.
enlaces externos (PAGE LINKS: EXTERNAL LINKS)
Marcando esta opción, Screaming Frog crawleará links externos, es decir, de dominios diferentes al que hayamos introducido. El rastreador, por defecto omite las directivas “nofollow” de los enlaces (tanto internos como externos), por lo que en caso de querer que sean seguidos, se deberá indicar expresamente.
A priori, es interesante usar esta opción para conocer el status de los enlaces que contiene la web, aunque sean externos, siempre será positivo asegurarse de que no dan error ni redirigen innecesariamente.
Cabe señalar que marcar esta opción nos va a condicionar dos elementos del panel derecho, por lo que esta información agrupará datos tantos de recursos internos como externos:
- Response codes
- Protocol
No obstante, no hay de qué preocuparse ya que la versión 19 incluye filtros para separar urls internas y urls externas, por lo que es algo en lo que Screaming Frog ha pensado y mejorado con el paso de las versiones.
Ejemplo de enlaces externos que podemos encontrar en una web:
- Links a otras webs de grupos (en otros dominios)
- Links a los perfiles sociales
- Links de botones de compartir
- Links editoriales a recursos de interés
- Links a menciones o apariciones en prensa de la web
- Etc.
instrucciones canonical (PAGE LINKS: CANONICALS)
Marcando esta opción, Screaming Frog rastreará las urls contenidas en marcado canonical (html o cabecera http) y estarán disponibles en la interfaz de la herramienta una vez finalice el rastreo.
Si solo se selecciona «store», las urls contenidas en «canonicals» seguirán apareciendo en la interfaz pero no se utilizarán para descubrir urls.
A priori esta opción es útil activarla en todos los casos (crawl & store).
marcado Paginación (PAGE LINKS: PAGINATION (REL NEXT / REL PREV))
Marcando esta opción, Screaming Frog rastreará las urls contenidas en el marcado de paginación y estarán disponibles en la interfaz de la herramienta una vez finalice el rastreo.
A priori esta opción es útil activarla cuando existe el marcado next/prev en el proyecto que vamos a analizar, sino existe paginación con dicho marcado, no tendrá efecto alguno en el rastreo, pero es preferible desactivarla.
marcado hrflang (PAGE LINKS: HREFLANG)
Marcando esta opción, Screaming Frog rastreará las urls contenidas en el marcado hreflang y estarán disponibles en la interfaz de la herramienta una vez finalice el rastreo.
De forma predeterminada, la herramienta extraerá los atributos contenidos en el hreflang y mostrará el idioma, los códigos de región y la url en la pestaña hreflang.
A priori esta opción es útil activarla en todos los casos en los que tengamos marcado internacional, sino no es necesario activarlo (crawl & store).
marcado amp (PAGE LINKS: AMP)
Marcando esta opción, la herramienta rastreará las urls contenidas en el marcado AMP y estarán disponibles en la interfaz de la herramienta una vez finalice el rastreo.
A priori esta opción es útil activarlo en los casos de medios de comunicación que aún usan AMP como versión alternativa, para ello, activar ambas opciones (crawl & store).
etiqueta meta refresh (PAGE LINKS: META REFRESH)
Marcando esta opción, la herramienta rastreará las urls contenidas en la etiqueta y estarán disponibles en la interfaz de la herramienta una vez finalice el rastreo.
¿Qué es una meta refresh?
Se trata de una redirección que ocurre del lado del cliente y que, a diferencia de las redirecciones 301 y 302 (del lado del servidor), el meta refresh le dice al navegador web que vaya a otra url después de un período de tiempo indicado en segundos. Si eligiéramos meta refresh 0, la redirección ocurriría de inmediato. Ejemplo de etiqueta:
<meta http-equiv="refresh" content="4; URL='https://www.mjcachon.com/que-es-meta-refresh'"/>Más info de la etiqueta aquí.
iframes (PAGE LINKS: IFRAMES)
Marcando esta opción, la herramienta rastreará las urls contenidas en la etiqueta iframe y estarán disponibles en la interfaz de la herramienta una vez finalice el rastreo.

¿Qué es un iframe?
Se suelen usar iframes para incrustar o embeber contenidos de otras webs y, dado que Google no entra a esos iframes, es recomendable no añadir en iframes información o contenido de valor, pues podría ser ignorado. No obstante, en enero de 2022 Google lanzó una nueva etiqueta meta para gestionar la indexación del contenido de iframes, la etiqueta meta se llama indexifembedded. Así, se podría indicar que se indexe el contenido de dentro de un iframe usando:
<meta name="googlebot" content="noindex" />
<meta name="googlebot" content="indexifembedded" />
<!-- OR -->
<meta name="googlebot" content="noindex,indexifembedded" />
Más info de la etiqueta aquí
MOBILE ALTERNATE (PAGE LINKS: MOBILE ALTERNATE)
Marcando esta opción, la herramienta rastreará las urls contenidas en la etiqueta link con el atributo rel=»alternate» y estarán disponibles en la interfaz de la herramienta una vez finalice el rastreo, aunque, normalmente, las webs que utilizan esas etiqueta suelen ser aquellas que tienen un html orientado a un dispositivo móvil y otro html para desktop, usando la etiqueta para referenciar ambas versiones.
Hay que considerar que desde 2020 Google anunció Mobile First Indexing, su enfoque orientado 100% a mobile, por lo que para la indexación se considera siempre la versión móvil de una web.
Puedes leer más sobre mobile first index aquí
COMPROBAR ENLACES FUERA DE LA CARPETA DE INICIO
(CRAWL BEHAVIOUR: CHECK LINKS OUTSIDE OF START FOLDER)
Marcar esta opción hace que la herramienta chequee enlaces independientemente de lo que hayas indicado como url de inicio, de este modo, podrías rastrear enlaces de todo el sitio, empezando desde cualquier parte.
RASTREAR FUERA DE LA CARPETA DE INICIO
(CRAWL BEHAVIOUR: CRAWL OUTSIDE OF START FOLDER)
Marcando esta opción, le damos la instrucción a Screaming Frog de rastrear más allá de la url o directorio de partida. Por tanto, si queremos rastrear solo las urls y contenidos de un directorio específico, deberemos desmarcar esta opción, para que no rastree otros directorios fuera del elegido.
Hay que tener en cuenta que esta opción puede colisionar con otras opciones del comportamiento del rastreo y generar rastreos descontrolados o que no respetan al 100% lo que quieres hacer.
EXTRACCIÓN (SPIDER EXTRACTION)
PAGE DETAILS
En este bloque vamos a poder configurar a medida qué elementos queremos extraer del rastreo, es decir, qué estará disponible en la interfaz y en los archivos descargables. Estamos hablando de elementos como:
- TITLE: extrae el contenido dentro de la etiqueta <title></title>.
- META DESCRIPTION: extrae el contenido dentro de la etiqueta <meta name=»description»>
- META KEYWORDS: extrae el contenido dentro de la etiqueta <meta name=»keywords»>
- H1: extrae el contenido dentro de la etiqueta <h1>
- H2: extrae el contenido dentro de la etiqueta <h2>
- INDEXABILITY: indica el estado de indexabilidad de cada url, en base a componentes como Status Code, valor del Meta Robots, valor del Canonical.
- WORD COUNT: extrae un valor aproximado del recuento de palabras que se encuentra en el texto rastreado. Ojo, porque en ocasiones la aproximación dista mucho de la realidad, por lo que es aconsejable hacer uso de la opción Custom Extraction con Xpath o Regex, para capturar el dato más realista.
- READABILITY: índice de legibilidad basado en el scoring de Flesch Kincaid, pero ojo, solo es aplicable a textos en inglés.
- TEXT TO CODE RATIO: extrae el ratio entre el texto y el código, por lo que te puedes hacer una idea de si hay más código que texto en cada url.
- HASH VALUE: es un id que se otorga a cada archivo como si fuera una «huella digital», se utiliza principalmente para identificar páginas duplicadas exactas.
- PAGE SIZE: tamaño del archivo en bytes por lo que si quieres el dato en kilobytes debes dividir por 1024. Además se ofrecerán un dato de «transferencia» (bytes requeridos para cargar el recurso) y un dato de tamaño del html sin comprimir.
- FORMS: extrae el contenido dentro de la etiqueta <form>
En el caso de los 5 primeros elementos, si ocurre que hay más de un elemento en el html rastreado, Screaming Frog te mostrará al menos los 2 primeros, por lo que es importante saber que en estos casos no estaríamos viendo el 100% de la realidad, solo una parte.
Por lo demás, si deshabilitas cualquiera de las opciones indicadas, no aparecerán en la interfaz de la herramienta después de terminar el rastreo. Tampoco aparecerán en las pestañas, columnas, filtros o informes.
El ejemplo más claro es que si deshabilitas la opción «Hash», ya no se podrá calcular la duplicidad exacta entre urls.
Por último, valora qué necesitas extraer realmente en tu rastreo y el resto, desmarcalo, conseguirás agiliar el rastreo, ahorrar memoria o no almacenar datos que en realidad no necesitas.
DETALLES DE LA URL (URL DETAILS)
En lo referente a detalles de la url, podemos configurar la extracción de los siguientes elementos:
- RESPONSE TIME: tiempo en segundos para descargar la url
- LAST MODIFIED: información tomada de la cabecera HTTP Last-Modified, si el servidor no proporciona ese valor, se quedará vacío el campo.
- HTTP HEADERS: extrae la petición HTTP completa y las cabeceras de respuesta
- COOKIES: se almacenan las cookies encontradas siempre que se utilice Rendering Javascript. Ojo, porque añadir el rastreo y extracción de cookies, sin afecta a cookies de medición, podría tener influencia en los datos de Google Analytics.
Nuevamente, evalúa qué necesitas extraer en tu rastreo y el resto, desmarcalo, conseguirás agilizar el rastreo y quizás ahorrar algo de memoria, pero los elementos dshabilitados para su extracción pueden influir en que no se calculen ciertas métricas o no aparezcan en informes, como decía antes.
DIRECTIVAS (DIRECTIVES)
En lo referente a directivas de la url, podemos centrarnos en los siguientes elementos:
- META ROBOTS: extrae el contenido dentro de la etiqueta <meta name=»robots»> (o en otros casos meta name=»googlebot», etc.)
- X-ROBOTS-TAG: valor de la directiva robots pero como elemento de la respuesta de cabecera HTTP de una URL determinada.
A priori esto son datos que siempre o casi siempre los vas a querer extraer, pero reitero que si no es algo estrictamente necesario, se puede omitir su extracción y aligerar el rastreo en términos generales.
DATOS ESTRUCTURADOS (STRUCTURED DATA)
Referente al marcado de datos estructurados se permite extraer el recuento de casuísticas en los distintos formatos, además de permitir hacer validación de si existen errores o sugerencia en cuanto a la implementación de dichos datos estructurados.
- JSON-LD: este es el formato recomendado por Google, es un script que se coloca en el código de cada url. Marcando esta opción, se extraerán todos los datos estructurados con este formato.
- MICRODATA:Marcando esta opción, se extraerán todos los datos estructurados con este formato.
- RDFA: Marcando esta opción, se extraerán todos los datos estructurados con este formato.
- SCHEMA.ORG VALIDATION: se realiza la validación contra la herramienta de schema.org
- GOOGLE RICH RESULT FEATURE VALIDATION: se realiza la validación contra la herramienta de Google.
- CASE-SENSITIVE: con esta opción eliges si quieres respetar mayúsculas y minúsculas o tratar todas las variantes como lo mismo.
HTML
También es posible configurar Screaming Frog para guardar el html plano y el renderizado, esto puede tener muchas utilidades de análisis por si mismo, pero en ocasiones, hay otras funcionalidades que precisan de esa configuración, por ejemplo el del análisis de N-Grams
- STORE HTML: si se marca esta opción se guarda el html plano, lo equivalente a si vas a una url y buscas su código fuente en el navegador.
- STORE RENDERED HTML: si se marca esta opción se guarda el html renderizado, lo equivalente a si vas a una url y buscas su código en el inspector de Chrome.
Una vez has rastreado un sitio con estas configuraciones, tendrás en el panel inferior la opción de ver el html guardado desde «Ver código» o «View source».
- STORE PDF: esta opción te permite guardar PDFs en tu equipo y acceder a ellos desde Bulk Export > Web > All PDF Documents, o si prefieres solo descargar su contenido, por Bulk Export > Web > All PDF Content.
- EXTRACT PDF PROPERTIES: por defecto, cuando marques esta casilla se extraen títulos y keywords de cada PDF, que aparecerá en los campos Title y Meta Keywords de la pestaña Internal. Además, también se extraerán otros elementos como Sujeto, Autor, Fecha de Creación, Fecha de modificación, Recuento de palabras y Recuento de páginas.
Una vez has rastreado un sitio con estas configuraciones, tendrás sus correspondientes columnas en la pestaña Internal.
LIMITES DEL RASTREO (SPIDER LIMITS)
La sección de límites es una estupenda configuración para poder personalizar hasta dónde queremos que llegue la herramienta en cada rastreo. El objetivo que tengamos con el rastreo podrá determinar que limitemos por longitud de urls, por tamaño del html, por número de urls o por profundidad, entre otros ejemplos.
Es una de esas armas a nuestra disposición para no perder tiempo rastreando grandes cantidades de información de forma innecesaria, incluso para evitar saturar equipos.
LIMITAR EL RASTREO TOTAL (LIMIT CRAWL TOTAL)
La versión gratuita de Screaming Frog te limitará por defecto a 500 URL, pero si tienes la versión de pago de la herramienta, podrás llegar a rastrear hasta 5 millones de URL.
LIMITAR PROFUNDIDAD (LIMIT CRAWL DEPTH)
La profundidad de rastreo se entiende como el número de enlaces desde el punto de partida, por lo que podemos limitar a cuántos clics de distancia queremos que llegue el rastreo, indicando el número que queramos en este campo, en conjunción con la url que añadamos como punto de partida, en el combo principal.
LIMITAR URLS POR PROFUNDIDAD (LIMIT URLS PER CRAWL DEPTH)
Esta opción también permite personalizar aún más el número de urls que queremos limitar en cada nivel de profundidad.
LIMITAR PROFUNDIDAD MÁXIMA DE CARPETAS (LIMIT MAX FOLDER DEPTH)
También podemos establecer el límite en base al número de carpetas o directorios que tenga una url, por ejemplo:
www.dominio.es/comprar/telefonos/moviles/smartphones/xiaomi/
En este ejemplo tenemos:
– la carpeta 1: comprar
– la carpeta 2: telefonos
– la carpeta 3: moviles
– la carpeta 4: smartphones
– la carpeta 5: xiaomi
De este modo, podríamos querer rastrear solo hasta el nivel 3, para no llegar a urls demasiado profundas, en base a su estructura de urls.
LIMITAR EL NÚMERO DE PARÁMETROS (LIMIT NUMBER OF QUERY STRINGS)
También existe la posibilidad de excluir urls parametrizadas, lo que nos da una flexibilidad enorme para evitar concatenación de filtros que a veces supone una generación exponencial de urls.
El aspecto de una url con 3 parámetros podría ser: ?param1=valor¶m2=valor¶m3=valor
Tendríamos en nuestra mano la opción de descartar urls de un número determinado de parámetros.
LIMITAR POR PATH DE URL (LIMIT BY URL PATH)
REDIRECCIONES MÁXIMAS A SEGUIR (MAX REDIRECT TO FOLLOW)
LONGITUD MÁXIMA DE URL PARA RASTREAR (MAX URL LENGTH TO CRAWL)
ENLACES POR URL MÁXIMOS PARA RASTREAR (MAX LINKS PER URL TO CRAWL)
TAMAÑO DE PÁGINA MÁXIMO PARA RASTREAR (MAX PAGE SIZE (KB) TO CRAWL)
SPIDER RENDERING
En esta sección se configura la forma en la que el robot que usemos va a rastrear: puede ser modo texto, modo ajax o modo javascript, siendo los más comunes el Texto y el Javascript.
Además, el render JS lo necesitaremos para utilizar ciertas funcionalidades (custom Javascript, por ejemplo).
Cuando elegimos Texto o Ajax, no hay más opciones añadidas para configurar, pero cuando elegimos render Javascript, si, por eso lo voy a explicar en el siguiente punto.
RENDERING: JAVASCRIPT
Cabe mencionar que usar este modo nos acerca más a la forma que tiene Google realmente de rastrear, además, también podríamos verlo como una manera de inspeccionar urls «con los ojos de Google», en bulk, o también, en vez del inspector de urls de Google Search Console, aquí podríamos tener el código renderizado del mismo modo.
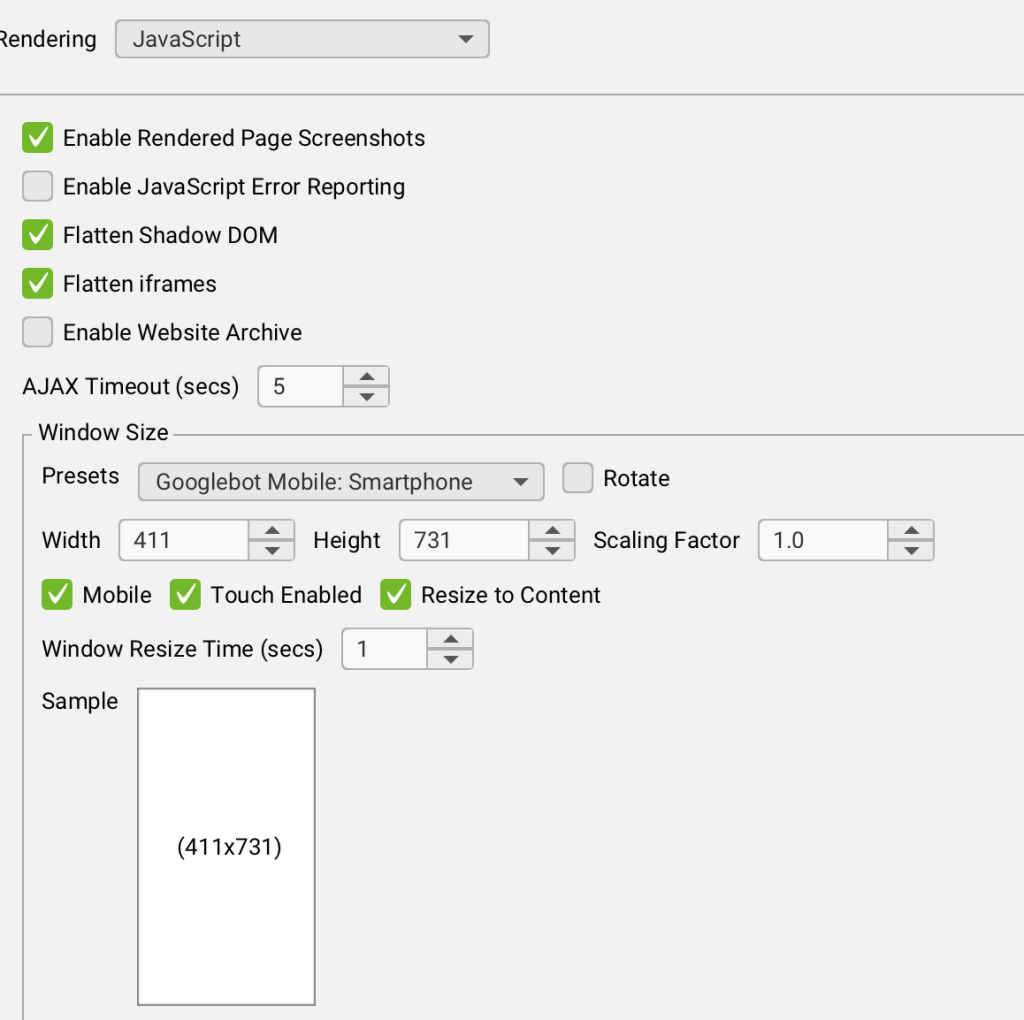
Algunas de las configuraciones disponibles son:
- Permitir pantallazos de página renderizada
- Permitir seguimiento de error de JS
- Flatten Shadow DOM
- Flatten iframes
- Habilitar Website Archive
- Ajax Timeout
- Window size
OPCIONES AVANZADAS (SPIDER ADVANCED)
ALMACENAMIENTO DE COOKIES (COOKIE STORAGE)
IGNORAR URLS NO INDEXABLES PARA ISSUES (IGNORE NON-INDEXABLE URLS FOR ISSUES)
IGNORAR URLS PAGINADAS PARA FILTROS DE DUPLICIDAD (IGNORE PAGINATED URLS FOR DUPLICATED FILTERS)
SEGUIR SIEMPRE REDIRECCIONES (ALWAYS FOLLOW REDIRECTS)
SEGUIR SIEMPRE CANONICALS (ALWAYS FOLLOW CANONICALS)
RESPETAR NOINDEX (RESPECT NOINDEX)
RESPETAR CANONICALS (RESPECT CANONICALS)
RESPETAR MARCADO NEXT/PREV (RESPECT NETX/PREV)
RESPETAR POLÍTICA HSTS (RESPECT HSTS POLICY)
RESPETAR META REFRESH AUTORREFERENCIADOS (RESPECT SELF REFERENCING META REFRESH)
EXTRAER IMÁGENES DEL ATRIBUTO SRCSET (EXTRACT IMAGES FROM SRCSET ATTRIBUTE)
RASTREAR FRAGMENTO DE IDENTIFICACIÓN (CRAWL FRAGMENT IDENTIFIERS)
EJECUTAR VALIDACIÓN HTM (PERFORM HTML VALIDATION)
TIEMPO DE RESPUESTA (RESPONSE TIMEOUT)
REINTENTOS DE RESPUESTA 5XX (5XX RESPONSE RETRIES)
PREFERENCIAS DE RASTREO (SPIDER PREFERENCES)
PAGE TITLE WIDTH
META DESCRIPTION WIDTH
LINKS
OTHER
CONTENT
ROBOTS.TXT
URL REWRITING
CDN
INCLUDE / EXCLUDE
SPEED
USER-AGENT
HTTP HEADER
CUSTOM
CUSTOM SEARCH
CUSTOM EXTRACTION
CUSTOM LINK POSITIONS
CUSTOM JAVASCRIPT
API ACCESS
AUTHENTICATION
SEGMENTS
CRAWL ANALYSIS
PROFILES
CONFIGURATION > LOAD
CONFIGURATION > LOAD RECENT
CONFIGURATION > SAVE AS
Dado que podemos hacer múltiples configuraciones, podemos guardarlas con un nombre fácil de identificar e ir cargándolas en función del objetivo de rastreo que tengamos.
Dos ejemplos claros:
– Análisis en bruto: para identificar el contenido de las etiquetas del sitio y ver si es correcto o incorrecto. Ejemplo de configuración:
– Análisis emulando el comportamiento de googlebot. Podemos tratar de imitar el rastreo que haría el bot de Google y chequear cómo pasa por el sitio web de análisis. Ejemplo de configuración:
Con esto claro, ya podemos aprovechar esta funcionalidad para guardar los ajustes de configuración y cargarlos cuando corresponda, para no tener que configurar cada rastreo cada vez.
Lo hacemos pulsando en File > Configuration > Save As
CONFIGURATION > SAVE CURRENT CONFIG AS DEFAULT
Con esta opción podemos hacer dos cosas:
– Establecer la configuración que estemos usando, como la predeterminada
– Resetear la configuración que estemos usando
En los siguientes epígrafes del manual, entenderemos mejor los efectos de estas opciones, pero podemos decir que no es lo mismo configurar Screaming Frog para que siga las redirecciones que no las siga, o para que respete las etiquetas canonical, por ejemplo.
Así, en función del objetivo que tengamos con el crawleo, tendremos que configurar específicamente la herramienta, antes de empezar a crawlear el sitio en cuestión.
Para las 2 opciones que comentábamos, tan solo hay que seleccionar la que queramos tal y como se muestra en la imagen:
CONFIGURATION > CLEAR DEFAULT CONFIG
Esta opción sestá disponible para configuración de almacenamiento Memoria y Base de datos.
Esta opción es similar a Open Recent, pero en este caso, no hace falta haber guardado un proyecto para volver a crawlear uno de los últimos sitios que hayamos analizado.
De este modo, podríamos usarlo como un acceso rápido a la lista de últimos sitios que hemos analizado, tal y como muestra el ejemplo:
Una vez pulsemos en uno de esos sitios, Screaming Frog comenzará a crawlear el sitio con la configuración que tuviéramos predeterminada.
BULK EXPORT
REPORTS
SITEMAPS
VISUALISATIONS
CRAWL ANALYSIS
LICENSE
WINDOW
HELP
PANEL CENTRAL
Ahora vamos a ver pestaña a pestaña qué tablas y filtros nos vamos a encontrar en cada caso, para saber qué podemos esperar a nivel de datos, una vez el rastreo o crawleo ha terminado y nos disponemos a revisar la información, procesarla en Screaming Frog o bien, exportarla y hacerlo en Excel, Google Spreadhseets u otros medios.
INTERNAL
La pestaña internal es donde se ubican la mayor parte de los datos del rastreo, solo están excluidos aquí los datos de External, Hreflang y Structured Data, por lo tanto, trabajar con los datos de esta pestaña nos daría la visión global del crawleo casí al completo (salvo las excepciones comentadas).
Esta sección está compuesta por las siguientes columnas:
- Address: la url rastreada.
- Segments: si has configurado la opción de Segmentos, aquí aparecerá la coincidencia y el color elegido.
- Content Type: el tipo de contenido.
- Status Code: el código de la respuesta HTTP. Ejemplo: 200, 301 o 404
- Status: la respuesta del encabezado HTTP. Ejemplo: OK, Moved Permanently o Not Found.
- Indexability: indica si la url es indexable o no indexable .
- Indexability Status: indica la razón por la que una url no es indexable. Por ejemplo, si está canonicalizada a otra url.
- Title 1: el primer título descubierto en la página (en el caso de que se encuentren varios).
- Title 1 Length: la longitud de caracteres del título de la página.
- Title 1 Pixel Width: el ancho en píxeles del título de la página (Screaming Frog tiene su propio enfoque para determinar qué ancho usar en base a lo que se muestra en las SERPs de Google, más info aquí) .
- Meta description 1: la primera meta descripción encontrada (en caso de haber más de 1).
- Meta description 1 Length: la longitud de caracteres de la meta descripción.
- Meta description 1 Pixel Width: el ancho de píxel de la meta descripción.
- Meta keywords 1: las meta keywords, a pesar de ser una etiqueta «obsoleta» para Google, para otros buscadores como Yandex, sigue estando en vigor. No obstante, muchas webs siguen usándola y quizás puede ser una forma de inferir qué importancia le dan esas webs a determinadas keywords.
- Meta keywords 1 Length: la longitud de caracteres de las meta keywords.
- H1 – 1 – El primer h1 encontrado de la página.
- H1 – Length 1 – La longitud en caracteres del h1.
- H2 – 1 – El primer h2 encontrado de la página.
- H2 – Length 1 – La longitud en carácteres del h2.
- Meta Robots 1: directivas de meta robots que se encuentran en el html de la página.
- X-Robots-Tag 1: directivas de meta robots que se encuentran en el encabezado HTTP de la petición.
- Meta Refresh 1: meta refresh es una forma de hacer redirecciones mediante una meta etiqueta, en este campo aparecerá el valor de dicha meta etiqueta.
- Canonical Link Element 1: el valor de la etiqueta rel canonical.
- rel=“next” 1: el valor de la etiqueta rel next (para indicar cuál es la url siguiente en una secuencia de urls) cuando existe paginación y se ha implementado esa configuración. Google confirmó que lleva años sin usar esas etiquetas, aunque eso no implica que haya que invertir tiempo en retirar los marcados .
- rel=“prev” 1: el valor de la etiqueta rel prev (para indicar cuál es la url previa en una secuencia de urls) cuando existe paginación y se ha implementado esa configuración.
- HTTP rel=“next” 1: mismo que lo comentado pero revisando la cabecera HTTP de la petición.
- HTTP rel=“prev” 1: mismo que lo comentado pero revisando la cabecera HTTP de la petición.
- Size: el tamaño del contenido de la página rastreada usando Content Length del encabezado HTTP. Si no estuviera ese campo se indicará que el tamaño es cero. Para las páginas HTML el tamaño está en bytes, así que se debería dividir entre 1024 para convertirlo a kilobytes.
- Transferred: la cantidad de bytes que realmente se transfirieron para cargar el recurso, que podría ser menor que el «tamaño» si se comprime.
- Word Count: son todas las «palabras» (texto dividido por espacios) dentro de la etiqueta <body> excluyendo el marcado HTML. El recuento se basa en lo que hayas configurado en «área de contenido» (‘Configuración > Contenido > Área’). Por defecto, la configuración de Screaming Frog excluye menús y footers. Considera que puede haber ciertas diferencias que si lo calculas manualmente ya que también se excluyen marcados no válidos o puede haber diferencias cuando se configura el rastreador en modo renderizado JS.
- Sentence Count: recuento de frases
- Average Words Per Sentence: palabras por frase
- Flesch Reading Ease Score: este score de legibilidad es solo válido para idioma inglés, por el momento, así que no lo tengas en cuenta si tu contenido es de otro idioma.
- Readability: mismo que lo anterior.
- Text ratio: caracteres no html / caracteres totales de la página rastreada.
- Crawl Depth: profundidad de la página desde la página de inicio (número de clics desde la página de inicio). Ten en cuenta que se tienen en cuenta también las redirecciones.
- Folder Depth: profundidad de la url basada en la cantidad de carpetas o path (/subcarpeta/) que tenga la url. Este aspecto puede ser útil para hacer la segmentación, pero no es una métrica SEO relevante ni tiene mucho impacto en rankings.
- Link Score: es una métrica propia de Screaming Frog que ofrece un valor entre 0 y 100, ese valor calcula una puntuación relativa de una url en función de sus enlaces internos (algo similar al PageRank de Google). Para calcularse es necesario hacer el post crawleo a través de la opción crawl analysis o análisis de rastreo.
- Inlinks: número de enlaces que recibe la url, desde el mismo subdominio que se ha rastreado.
- Unique Inlinks: número de enlaces internos únicos que recibe la url, por ejemplo, la url 1 enlaza con la url 2 10 veces, esto significarían 10 inlinks y 1 unique inlink para la url 2.
