

Disclaimer: for a better browsing experience, you can rotate your mobile and the data will look pretty good, but if you want a perfect navigation, I invite you to navigate from your computer and click “toggle fullscreen”.
How I created the app
The full web app is built with Lovable.
After extracting the contents and tagging them by blog, year and author, I mainly used the ™ library in Rstudio to analyse the texts.
The first part is to clean it all up by removing stop words, converting to lowercase, etc.
With this clean list of words, the most repeated words can be extracted and with the use of filters, it is more useful to go to specific years, check authors or compare.
Then, proprietary table libraries such as DT have been used to build tables that allow html to be added and logos to be displayed, such as the lot Top Contributors for each blog selection and year.
Regarding the Sentiment Analysis tab, the TidyText library is used to extract the sentiments with the “bing” lexicon, to classify the words used with negative or positive sentiment.
In both analyses, graphs and summary tables are included.
I have ruled out adding part of speech or co-occurrence analysis because for a dataset of thousands of texts I would need to look for solutions that do not consume so many resources and my programming skills do not allow me to add anything else.
And now only the most important thing remains: practising the pronunciations to improve my speaking skills.
What to analyse
1) The first thing to build my personal project was to choose some of the blogs I always read. Sistrix, Screaming Frog, Semrush, Ahrefs…. and Google also came to mind. If you want to suggest me to add more blogs, just let me know :)
2) Then I only set myself the goal of extracting the most used words, but once I had blogs, authors and years of publication, I thought it would be a good idea to combine the 3 data.
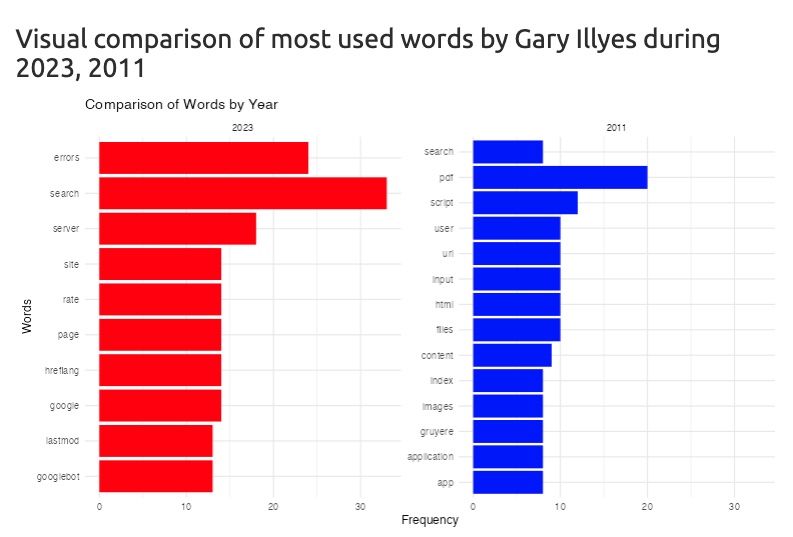
3) Using R and Shiny, I have been able to create a graph and some general or author tables, to know which words each person uses in each year. For example, what Gary Illyes wrote on the blog in 2023 vs. 2011. Quite interesting, right?
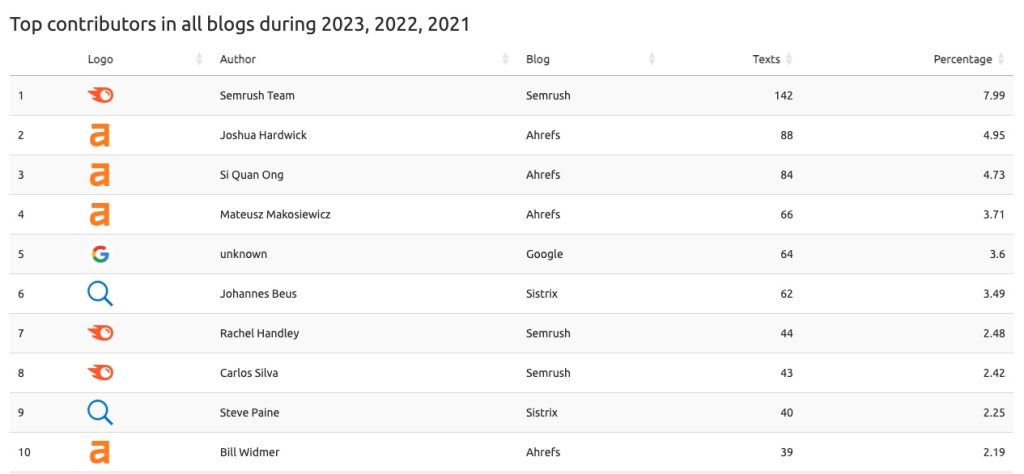
4) You can even see which blog produced the most content at a particular point in time and which authors gave their hugue contribution (in cuantitative terms)
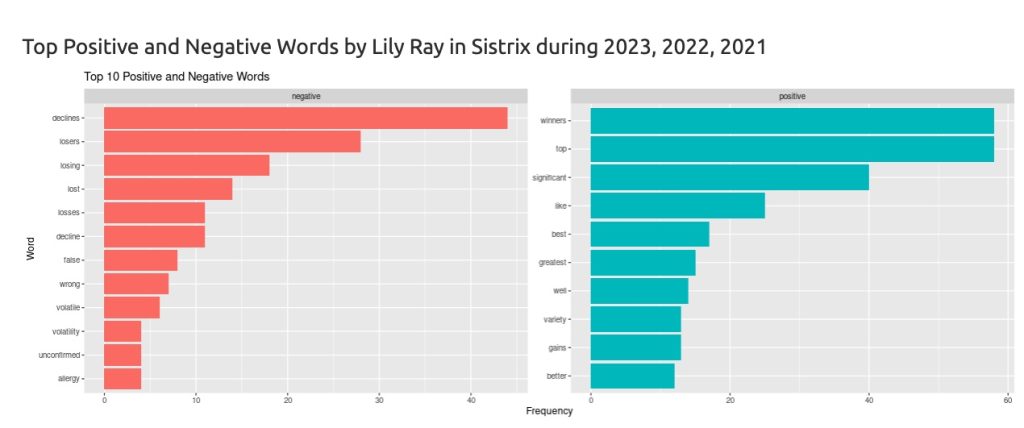
5) One more thing, why not also show the breakdown of feelings with positive and negative words?
Sometimes the data analysis speaks for itself, my friend Lily Ray is still the best analyst on Google Updates 🩵
I could have added part-of-speech analysis, co-occurrence analysis or n-gram analysis, but sometimes simple things are already useful (In fact, I tried it, but I didn’t find a really coherent way in performance and processing).
Now you can use it to have fun or to find patterns, or like me, to improve your English communication skills by better pronunciation, I just ask you to be patient when choosing the filters, it takes a few seconds to display the information.
And if you find any mistakes, I appreciate the comments!