

El enlazado interno es uno de los ejes fundamentales para potenciar la experiencia del usuario y mejorar el SEO de una web. Sin embargo, no basta con añadir enlaces a lo loco, tenemos que saber dónde y sobre todo debemos saber por qué.
En este artículo, voy a usar dos métricas super fáciles, a través de datos que están a tiro de piedra en cualquier rastreo que hagamos con Screaming Frog:
- Clicks: cuántos clicks ha recibido una URL en cuestión, en el periodo que hayamos estimado. Este dato se obtiene de Google Search Console.
- Unique Inlinks: cuántos enlaces internos únicos recibe esa URL. Este dato se obtiene del rastreo con Screaming Frog (o el crawler que utilices).
El resultado de combinar ambas nos ayudará a priorizar qué páginas necesitan más atención y cuáles quizás ya destacan… aunque podrían crecer aún más con un apoyo interno adicional.
Para este artículo vamos a obviar el dato de Enlaces Externos Entrantes, que sería «la fuerza» con la que cuenta cada URL para distribuir hacia dentro del sitio, no obstante, si sigues la lógica que cuento aquí, podrás añadir todas las métricas que quieras.
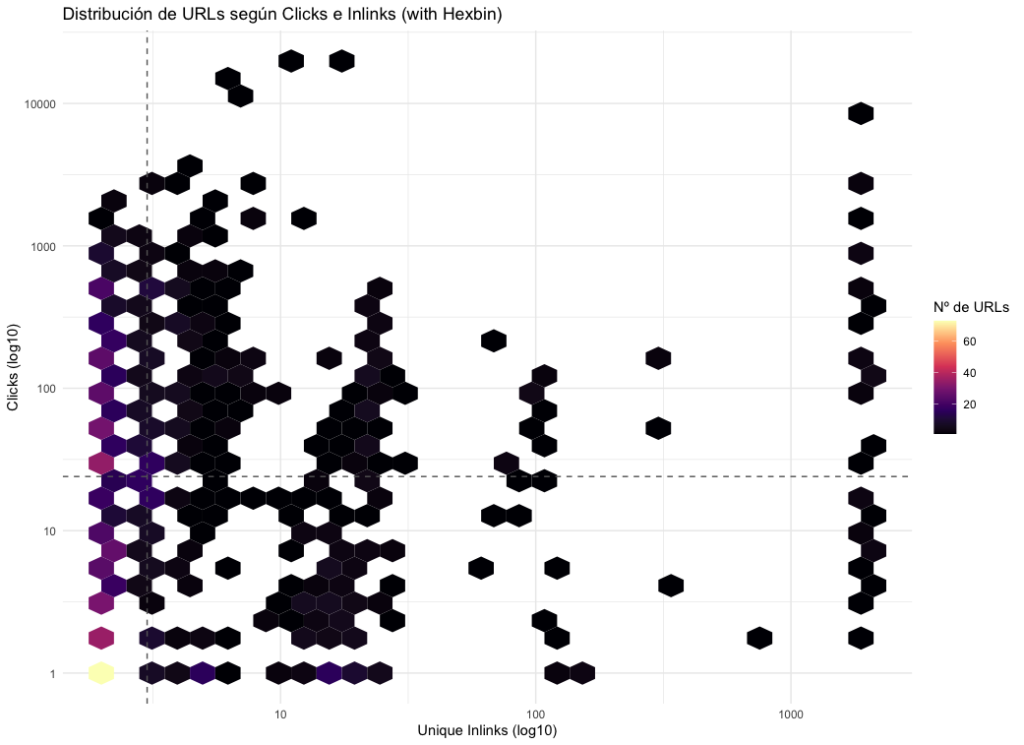
Crear el ratio “Clicks por Unique Inlink”
La pregunta clave es: “¿Consigue cada URL suficientes clics en relación con la cantidad de enlaces internos que recibe?”
Este ratio lo que hace es dividir los Clicks por el dato de Unique Inlinks, a partir de esto podemos entender la magnitud el ratio tal que:
- Alto ratio: páginas que consiguen muchos clicks, con pocos enlaces. Significa que estas páginas son efectivas e interesantes, logran captar tráfico aunque no las estamos potenciando con enlazado.
- Bajo ratio: páginas que apenas generan clicks pero reciben muchos enlaces internos. Estaríamos hablando de «despilfarro», ineficiencia o priorización equivocada de enlazado. Puede que la página si merezca los enlaces internos pero tenga otros problemas. O puede que no debería tener tantos enlaces.
Con este ratio no solo identificamos el potencial sino que nos muestra la efectividad. En ambos casos nos ayuda a potenciar lo que toca, al menos es el primer paso para descubrir gaps en positivo y en negativo.
Una forma ágil de ilustrar esto es crear un listado de Top Urls y de Bottom Urls, para entender cuáles están a qué nivel de ratio.
Un ejemplo utilizando R:
##################################################
# 1) CALCULAR RATIO "CLICKS POR UNIQUE INLINK"
##################################################
df$Clicks_per_UniqueInlink <- df$Clicks / df$`Unique Inlinks`
df$Clicks_per_UniqueInlink[is.infinite(df$Clicks_per_UniqueInlink)] <- NA
df$Clicks_per_UniqueInlink[is.na(df$Clicks_per_UniqueInlink)] <- 0
##################################################
# 2) FILTRAR FILAS CON MÁS DE 0 CLICKS
##################################################
filtered_df <- subset(df, Clicks > 0)
##################################################
# 3) ORDENAR POR MAYOR RATIO Y TOP 10 GLOBAL
##################################################
high_ratio <- filtered_df[order(-filtered_df$Clicks_per_UniqueInlink), ]
top_10_high_ratio <- head(
high_ratio[, c("Address", "Segments", "Clicks", "Unique Inlinks", "Clicks_per_UniqueInlink")],
10
)Este ejemplo nos ofrece una lista de las páginas con Alto Ratio, en base a los datos que le hayamos prorpocionado :)
Usar la mediana para comparar:“muchos clics / pocos inlinks” y viceversa
Como método adicional, podemos usar la mediana global de todas las urls para comparar con los casos individuales de las urls. De este modo:
- Calculamos la mediana de Clicks global
- Calculamos la mediana de Unique Inlinks global
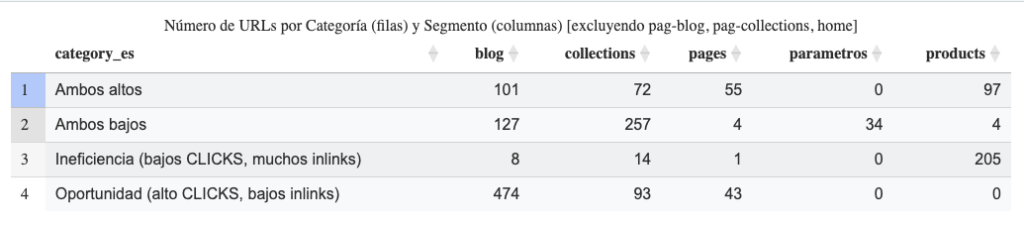
Tendríamos 4 posibles grupos:
- Muchos clics y muchos inlinks: equilibrio, está todo correcto.
- Muchos clics y pocos inlinks: ey, potenciemos estas páginas
- Pocos clics y muchos inlinks: ¿estamos sobreenlazando estas páginas?
- Pocos clics y pocos inlinks: ¿es residual, de nicho o necesita consolidarse con otras páginas?
Una idea para hacer el segundo escenario en R:
##################################################
# 2) DETECTAR "MUCHOS CLICKS Y POCOS UNIQUE INLINKS" SEGÚN MEDIANA
##################################################
median_clicks <- median(df$Clicks, na.rm = TRUE)
median_unique_inlinks <- median(df$`Unique Inlinks`, na.rm = TRUE)
high_clicks_low_inlinks <- subset(
df,
Clicks > median_clicks & `Unique Inlinks` < median_unique_inlinks
)
high_clicks_low_inlinks <- high_clicks_low_inlinks[order(-high_clicks_low_inlinks$Clicks),
c("Address","Segments","Clicks","Unique Inlinks",
"Crawl Depth","Link Score")]Si además tienes el Segmento en tu dataset, pues te servirá para priorizar por aquellas tipologías de páginas que más te interese.
Análisis por segmentos o tipos de página
Para ir a algo más específico y poder descender en el análisis, podemos agrupar las URLs por su segmento o tipología. En mi ejemplo, he usado una web del sector de segunda mano hecha en Shopify:
- Collections (categorías o listados de producto). La propia url ya tiene un path específico.
- Products (fichas individuales de productos). La propia url ya tiene un path específico.
- Blogs (artículos). La propia url ya tiene un path específico.
- Pages (páginas estáticas, como Contacto, pero también podrían ser «listados» encubiertos). La propia url ya tiene un path específico.
Esto es útil porque podemos comparar la media de ratio o de clics entre distintos segmentos para ver dónde optimizar primero.
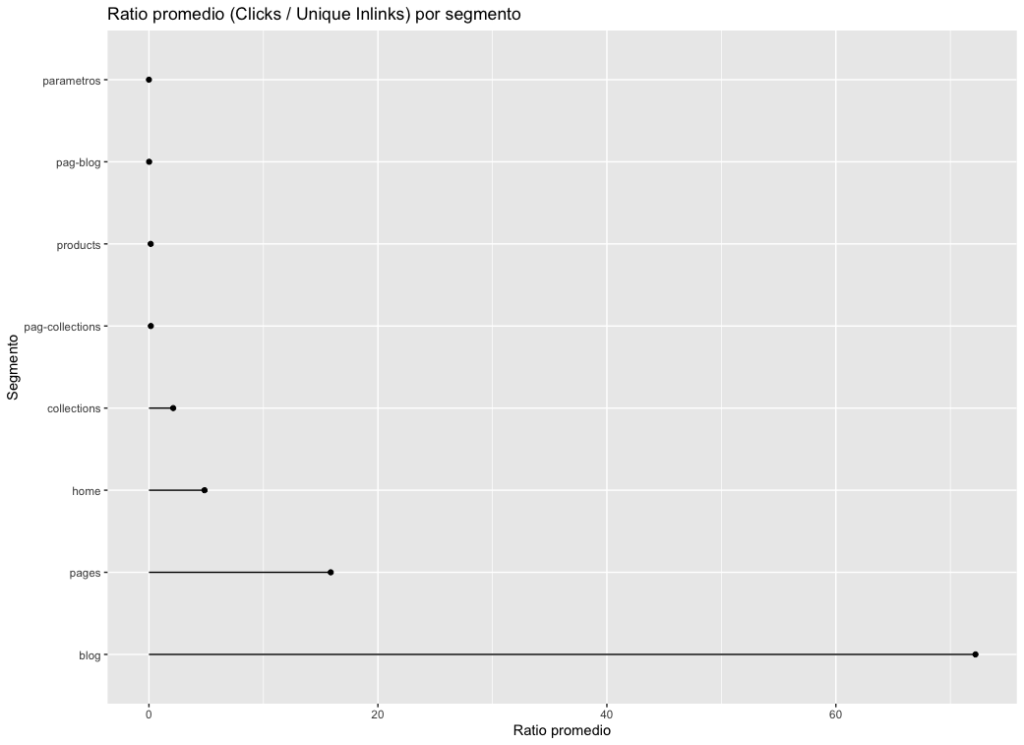
Saber en qué segmento hay más oportunidades es de mucho valor, así como identificar si los artículos del blog tienen tracción sin necesidad de muchos enlaces internos.
Un ejemplo en R, mi lenguaje habitual:
##################################################
# 3) ANÁLISIS A NIVEL DE SEGMENTO
##################################################
# Estadísticas por segmento
df_segment_stats <- df %>%
group_by(Segments) %>%
summarise(
total_urls = n(),
sum_clicks = sum(Clicks, na.rm = TRUE),
mean_clicks = mean(Clicks, na.rm = TRUE),
median_clicks = median(Clicks, na.rm = TRUE),
sum_unique_inlinks = sum(`Unique Inlinks`, na.rm = TRUE),
mean_unique_inlinks = mean(`Unique Inlinks`, na.rm = TRUE),
median_unique_inlinks = median(`Unique Inlinks`, na.rm = TRUE),
mean_ratio = mean(Clicks_per_UniqueInlink, na.rm = TRUE),
median_ratio = median(Clicks_per_UniqueInlink, na.rm = TRUE),
.groups = "drop"
)
# Top 5 URLs de cada segmento por ratio
df_top5_by_segment <- df %>%
filter(Clicks > 0) %>%
group_by(Segments) %>%
arrange(desc(Clicks_per_UniqueInlink)) %>%
slice_head(n = 5) %>%
select(Address, Segments, Clicks, `Unique Inlinks`, Clicks_per_UniqueInlink)
cat("\n=== TOP 5 POR SEGMENTO (ratio CLICKS/INLINKS) ===\n")
print(df_top5_by_segment)
# Bottom 5 URLs de cada segmento por ratio
df_bottom5_by_segment <- df %>%
group_by(Segments) %>%
arrange(Clicks_per_UniqueInlink) %>%
slice_head(n = 5) %>%
select(Address, Segments, Clicks, `Unique Inlinks`, Clicks_per_UniqueInlink)Podemos llevarlo al nivel que queramos, con las métricas que queramos, con una simplicidad enorme simplemente comparando valores altos y bajos de las métricas elegidas.
Conclusiones y siguientes pasos
En análisis de datos a veces la estadística básica puede darnos buenísmas opciones o convertirse en una solución para ser más ágiles en la detección de oportunidades o de ineficiencias, sin necesidad de lanzar análisis sobredimensionados con aprendizaje automático o inteligencia artificial.
La gran ventaja es que se puede reproducir muy bien en cualquier lenguaje de programación y mucho más importante, ¡hasta en Excel!
Como siguientes pasos, y unido al análisis de correlación del último artículo, seguro estamos en disposición de empezar a pensar en regresiones líneales, para continuar con análisis más profundos.
¡Hasta el próximo artículo!
¿Cuánto tiempo me ha llevado crear este artículo?
Pues menos de lo que creía, la verdad :)
Ya hace años di una charla sobre Enlazado Interno y en ella cuento muchas formas de cruzar métricas.
Con esa base, he aterrizado este artículo con algo de estadística y de R, ¡que gusto!
Bueno, que me enrollo, creo que unas 2 horas en total, entre redactar, escribir el código, comprobar que todo iba bien y levantarme a por coca cola :D
¡Espero que haya sido útil, por el camino sonaba música de Siloé!
Soy MJ Cachón
Consultora SEO desde 2008, directora de la agencia SEO Laika. Volcada en unir el análisis de datos y el SEO estratégico, con business intelligence usando R, Screaming Frog, SISTRIX, Sitebulb y otras fuentes de datos. Mi filosofía: aprender y compartir.
Explorar por temas
tal vez sea
de tu interés
-

Optimizar contenidos usando datos de la API de Search Console y R
En este artículo de Kevin Indig sobre Content Tuning con la API de Google Search Console y el conector de Google Sheets, pues me he puesto como reto tratar de replicarlo en R. (Otra alternativa es esta presentación de Aleyda). Todo hay que decir que en esto no he estado sola, porque en los últimos tiempos … Optimizar contenidos usando datos de la API de Search Console y R
Leer artículo -
Usos de Excel en una Agencia de Marketing Online
Vamos a recopilar y enumerar las funciones más interesantes o usuales, desde el punto de vista operativo, del día a día en los respectivos trabajos y tareas, pero lógicamente solo atacaremos las principales, no todas las existentes.
Leer artículo -
Cambios en las Quality Raters Guidelines
Hoy quiero compartir los cambios que he identificado sobre las guidelines que Google ofrece a sus Quality Raters
Leer artículo