

Cuando nos enfrentamos al reto de estudiar la legibilidad de contenidos en proyectos web encontramos literatura y métricas notorias como Flesch Reading Ease. La importancia de estas métricas está en algo sencillo y que no deberíamos dejar de tener presente: si nuestros textos o contenidos no se entienden fácilmente vamos a perder a nuestros usuarios.
La legibilidad es una métrica que nos dice lo fácil que es leer y entender un texto, normalmente tendrá en cuenta la longitud de las frases, la complejidad de las palabras utilizadas y sobre todo, la estructura del lenguaje.
La métrica conocida por autonomasia es el Flesch Reading Ease, creada por Rudolf Flesch en 1948. Esta fórmula va a generar una puntuación que cuanto más alta sea, más fácil será leer el texto y nos servirá para identificar contenidos que pueden mejorarse y alinearse al nivel de nuestro público objetivo.
Relación de la legibilidad con el SEO
Llevamos años y años escuchando sobre EEAT, calidad de contenido y experiencia de usuario (UX) en todo lo referente a proyectos SEO. Si los buscadores premian los contenidos útiles, claros y suficientemente accesibles, la legibilidad puede ser un componente adicional a considerar o al menos, el punto de partida previo a analizar la calidad del contenido en si mismo.
Por otro lado, entender cómo interactúan los usuarios con nuestros contenidos puede ser clave para ofrecer los mejores contenidos, más fácilmente escaneables y sobre todo, comprensibles.
Cuando el texto es denso, mal estructurado o está lleno de tecnicismos innecesarios, genera fricción. Y donde hay fricción, el usuario abandona, desconfía o simplemente no entiende.
Además, en ciertos sectores complejos con que requieren un mayor nivel de investigación, motivación e incluso, atención, como los médicos o financieros, en los que el usuario puede partir de un nivel de conocimiento previo bajo, el lenguaje y redacción que usemos, puede complicarlo aún más.
Y recuerda, no escribimos simplemente por SEO, escribimos para conectar con el usuario y mostrarle que somos una opción para ellos, para eso hay que ser legibles, entendibles y mostrar todo nuestro expertise.
¿Por qué buscar alternativas para el idioma español?
La métrica original Flesch Reading Ease está pensada para el idioma inglés por lo que usarlo para el idioma español no es del todo fiable, sobre todo si nos fijamos en las diferencias entre ambos idiomas:
- En español hay frases mucho más largas
- Las palabras tienen más silabas
- Las estructuras sintácticas pueden resultar mucho más complejas
- Las conjugaciones verbales son más extensas
La justificación de crear este enfoque es que los idiomas son bastante diferentes:
Necesitamos un enfoque más granular y adaptado al idioma concreto, que evite lo sesgos al contener palabras más largas o palabras con mayor número de silabas.
Por estas razones, es mejor buscar una alternativa y no incurrir en «falsos positivos» o «falsos negativos» de legibilidad en nuestros proyectos en español.
¿Qué opciones tenemos como alternativa?
Flesch-Szigriszt
Una adaptación del índice Flesch al español es la fórmula matemática desarrollada por el investigador Pedro Szigriszt Pazos en 1993 que tiene en cuenta tiene en cuenta el número de palabras por frase y el número de sílabas por cada 100 palabras.
La fórmula que propone y sus coeficientes fueron ajustados empíricamente usando corpus españoles, por lo que esta adaptación no consiste en una mera traducción del índice Flesch basado en inglés.
Flesch-Fernández Huerta
Es una adaptación directa del Flesch Reading Ease, pero ajustada con pesos específicos para estructuras del español.
Es prácticamente la misma fórmula que Flesch-Szigriszt, pero aplicada con otra base de evaluación y es bastante común ver ambos autores relacionados.
A pesar de ello, es menos popular en la actualidad.
INFLESZ
Es una serie de métricas desarrolladas por Barrio-Cantalejo, que combina varias métricas para español sobre todo en el ámbito sanitario y académico. Probablemente en esos ámbitos sería el mejor método para usar.
No existe una fórmula pública tan clara y accesible como la de Flesch-Szigriszt, pero conceptualmente también usa sílabas/palabras/frases.
¿Por qué utilizar Flesch-Szigriszt?
Hay varias razones:
- Se ha testado en corpus reales de idioma español
- La interpretación es asequible y sencilla
- Es el más utilizado y popular
Podemos usar la fórmula original o la simplificada:
Fórmula original propuesta por Pedro Szigriszt Pazos en su tesis doctoral de 1993
Índice Flesch-Szigriszt = 206.835 − (62.3 × (sílabas / palabras)) − (palabras / oraciones)
Versión simplificada de la fórmula original de Pedro Szigriszt Pazos
Índice Flesch-Szigriszt = 206.84−(0.60×Sílabas por cada 100 palabras)−(1.02×Palabras por oración)
Ejemplo práctico
Si tuviéramos un texto con 100 palabras repartidas en 10 frases, esto supondría tener 10 palabras por cada frases. La fórmula de legibilidad original le restaría 10 puntos, en la simplificada 10,2.
Sin embargo si tuviéramos un texto con 100 palabras repartidas en 2 frases, esto supondría tener 50 palabras por frase. La fórmula de legibilidad original le restaría 50 puntos, en la simplificada 51.
El concepto es el mismo, el nivel de penalización puede variar.
Al final estos enfoques no hacen otra cosa que reafirmar las consecuencias que una redacción compleja puede tener en los usuarios:
- Sobrecarga cognitiva: cantidad de información para guardar en memoria
- Estructura compleja: lenguaje excesivamente subordinado
- Mayor riesgo de confusión: sería más fácil perderse en la lectura por la estructura
Interpretación de los datos
Usar la original o la simplificada dependerá de cómo de concisos queramos ser y del contexto del proyecto que analicemos.
Mientras que la simplificada está basada en coeficientes reescalados del modelo inglés y tiende a suavizar los resultados, pero puede fallar en textos con muchas palabras de más de 3 sílabas, la original está testada y validada en corpus en español, además de adaptarse de forma más exacta al lenguaje.
Sin embargo, para estudios o análisis de gran escala quizás es suficiente con usar la fórmula simplificada y si nos vamos a adentrar en estudios más académicos o de accesibilidad, podemos usar la fórmula original.
Para interpretar el índice Flesch-Szigriszt, cuanto más alto el valor, más fácil es de leer.
Tal y como recomienda Olga Carreras en su artículo sobre legibilidad:
«Si hubiera que seleccionar por tanto la fórmula más adecuada hoy en día para medir la legibilidad de textos en español, creo que podemos decir que sería la fórmula de Flesch-Szigriszt, pero usando para la interpretación de la puntuación obtenida la escala de Inflesz «.
Por tanto, estos serían los rangos de la puntuación y sus niveles de legibilidad o tipo de lector usando la escala de Inflesz:

Para interpretar los datos podemos establecer que textos para público general deberían estar a partir de 65.
En base al tipo de proyecto en el que estemos y el nivel de conocimiento de los usuarios, podríamos establecer nuestros propios rangos, por ejemplo, una temática técnica puede permitirse tener valores más bajos pero si los usuarios no son expertos, no podrán entender el contenido, son las dos variables a considerar.
Por ejemplo, para textos cuyos índices estén por debajo de 55 nos podemos plantear simplificar la sintaxis, reducir frases largas y evitar palabras complejas.
También esta métrica se puede usar en conjunto con otras técnicas de análisis cualitativo con usuarios, ya sea con grabaciones de usuarios, encuestas o sistemas de eye tracking.
Por último, es altamente recomendable tener presentes los patrones de consumo de contenido que hacen los usuarios online, como los patrones F y otros patrones que sugieren la existencia de factores por los que la gente escanea y no lee, entre otras cosas.
Como configurar Screaming Frog para analizar la legibilidad en idioma español: paso a paso
Dado que Screaming Frog aún no tiene una métrica específica para español podemos crearla a medida usando su opción Custom Javascript.
Voy a dar dos formas de hacerlo, en ambas, el path a seguir es el mismo, lo explico paso a paso.
Paso 1: configuración
Para usar esta funcionalidad es preciso utilizar renderizado JavaScript en:
Crawl Config > Spider > Rendering
Una vez hecho esto, ya podemos ir a nuestros snippets JavaScript desde:
Crawl Config > Custom > Custom JavaScript
Paso 2: añadir código desde cero o desde la librería
Llegaremos a algo como esto:
- Utilizamos «Add» cuando queremos crear un snippet JS desde cero, en blanco.
- Utilizamos «Add From Library» cuando queremos acceder a los snippets JS guardados que vienen por defecto o aquellos que hayas guardado previamente para usar más veces.
Ahora vamos a ver cómo es el panel donde subir nuestro codigo asumiendo que hemos elegido «Add» para empezar en blanco:
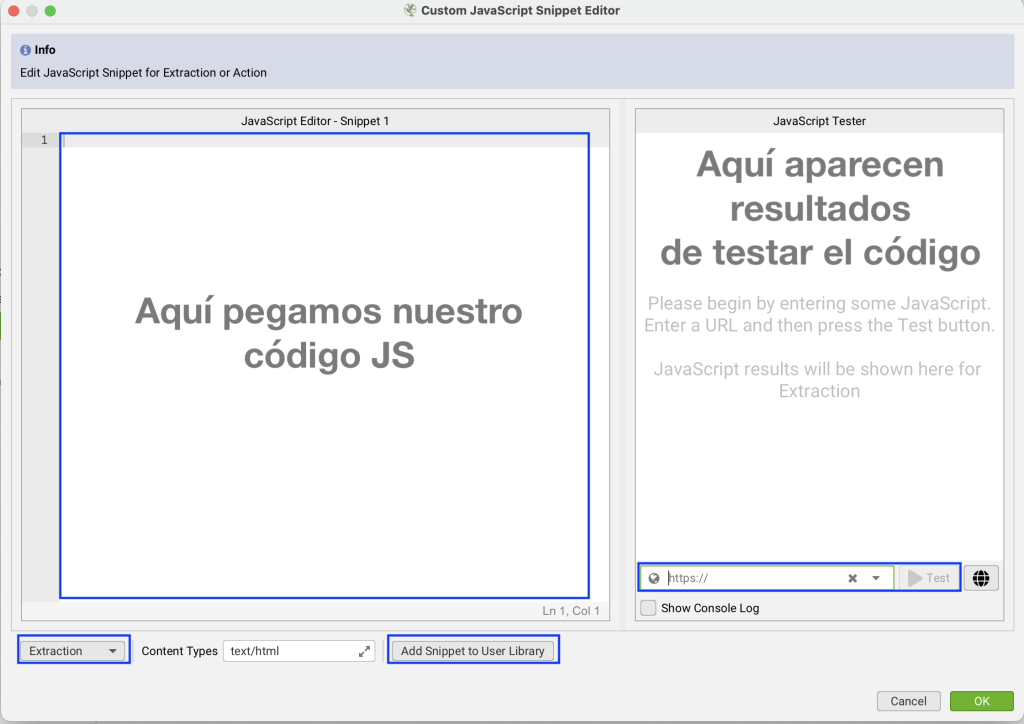
- El panel izquierdo es donde pegaremos nuestro código
- Podemos elegir si el snippet JS ha de extraer información (calcular y devolver el dato de legibilidad) o de llevar a cabo una acción (ejemplo: hacer scroll), hay más información de esto en la web oficial.
- También podemos elegir a qué tipo de contenido aplicar el snippet JS
- Si es un snippet común que solemos usar, podemos guardarlo en «Add Snippet to User Library», para acceder a él rápidamente en otros rastreos.
- Por último, en la zona derecha se podrán probar los snippet JS antes de rastrear la web, lo que es muy útil para detectar errores y no perder tiempo.
Paso 3: crear todos los que necesitemos y probarlos antes de rastrear el sitio
El resultado final sería algo como esto:
En mi caso he añadido 4 snippets, cuantos más añada, más lento irá el rastreo, tenlo en cuenta.
Ahora solo queda explicar cómo enfocar la creación del código para tener controlado el proceso y evitar falsos positivos o negativos.
2 metodologías de análisis de legibilidad en Screaming Frog
Para el análisis propongo dos formas de hacerlo, una primera en la que miramos todo el <body> para encontrar su contenido, juntarlo, eliminar espacios o saltos de linea, poner en minúsculas e incluso quitar acentos, como limpieza previa a realizar el cálculo del índice Flesch-Szigriszt.
Y una segunda en la que usaremos una expresión Xpath específica a la zona del html donde se encuentre el main content.
Por último, para tener una noción clara de las diferencias entre la fórmula original y la fórmula simplificada, voy a extraer ambos cáculos para las 2 metodologías propuestas
Método 1: basado en el contenido completo del body
Con estos códigos se extraerán todos los nodos del body y se hará la extracción y limpieza de texto para proceder a calcular el índice, todo en un solo paso.
Este primer código hace referencia a la fórmula original
// Índice de Flesch-Szigriszt (fórmula original de 1993)
function countSentences(text) {
return (text.match(/[.!?¡¿]+/g) || []).length || 1; // evitar división por 0
}
function countWords(text) {
return text.split(/\s+/).filter(Boolean).length;
}
function countSyllables(word) {
word = word.toLowerCase().normalize("NFD").replace(/[\u0300-\u036f]/g, ""); // quita tildes
const syllableGroups = word.match(/[aeiouáéíóúü]{1,2}/g);
return syllableGroups ? syllableGroups.length : 1;
}
function totalSyllables(text) {
const words = text.split(/\s+/).filter(Boolean);
return words.reduce((acc, word) => acc + countSyllables(word), 0);
}
// Extraer y limpiar texto del body
let bodyText = document.body.innerText
.replace(/\s+/g, ' ')
.replace(/[\r\n\t]+/g, ' ')
.trim();
// Cálculos base
let sentenceCount = countSentences(bodyText);
let wordCount = countWords(bodyText);
let syllableCount = totalSyllables(bodyText);
// Fórmula original: 206.835 - (62.3 * (sílabas/palabras)) - (palabras/oraciones)
let fleschSzigriszt = 206.835 - (62.3 * (syllableCount / wordCount)) - (wordCount / sentenceCount);
// Redondear
fleschSzigriszt = Math.round(fleschSzigriszt * 100) / 100;
// Devolver resultado
return seoSpider.data(fleschSzigriszt);
Este segundo código hace referencia a la fórmula simplificada
// Índice de Flesch-Szigriszt (fórmula simplificada)
function countSentences(text) {
return (text.match(/[.!?]+/g) || []).length || 1; // evita división por 0
}
function countWords(text) {
return text.split(/\s+/).filter(Boolean).length;
}
function countSyllables(word) {
word = word.toLowerCase().normalize("NFD").replace(/[\u0300-\u036f]/g, ""); // quita acentos
const syllableGroups = word.match(/[aeiouáéíóúü]{1,2}/g);
return syllableGroups ? syllableGroups.length : 1;
}
function totalSyllables(text) {
const words = text.split(/\s+/).filter(Boolean);
return words.reduce((acc, word) => acc + countSyllables(word), 0);
}
// Extraer texto limpio
let bodyText = document.body.innerText
.replace(/\s+/g, ' ')
.replace(/[\r\n\t]+/g, ' ')
.trim();
// Calcular elementos básicos
let sentenceCount = countSentences(bodyText);
let wordCount = countWords(bodyText);
let syllableCount = totalSyllables(bodyText);
// Calcular índice de Flesch-Szigriszt
let syllablesPerWord = syllableCount / wordCount;
let wordsPerSentence = wordCount / sentenceCount;
let fleschSzigriszt = 206.84 - (0.60 * syllablesPerWord * 100) - (1.02 * wordsPerSentence);
// Redondear
fleschSzigriszt = Math.round(fleschSzigriszt * 100) / 100;
// Devolver resultado
return seoSpider.data(fleschSzigriszt);
De manera adicional, aconsejo crear un código extra a modo de campo de control para entender sobre qué texto concreto se está generando el índice de legibilidad y chequear ante posibles datos extraños. Tan solo será necesario crear un custom Javasscript extra para poder consultarlo si necesitamos o siempre es factible extraer el contenido en bruto usando Xpath y Custom Extraction, ¡elige lo que prefieras!
// Extrae el texto visible del <body> y lo limpia para análisis
let bodyText = document.body.innerText
.replace(/\s+/g, ' ') // Unifica espacios, saltos de línea, tabs, etc.
.replace(/^\s+|\s+$/g, '') // Elimina espacios al principio y final
.normalize("NFD") // Normaliza acentos para legibilidad si se desea
.replace(/[\u0300-\u036f]/g, '') // (Opcional) Elimina tildes si lo quieres neutro
return seoSpider.data(bodyText);Método 2: basado en el Xpath personalizado donde se encuentre el contenido específico
Con esta versión de código se extraerán todos los nodos del Xpath indicado y se hará la extracción y limpieza de texto para proceder a calcular el índice.
Ten en cuenta que el código va a utilizar todos los nodos que cuelguen de la expresión Xpath, si solo quieres el primer nodo, tendrías que adaptar el código.
Este primer código hace referencia a la fórmula original
// Índice de Flesch-Szigriszt Original + XPath
let xpath = "//div[@class='left-column']//p";
// Funciones auxiliares (declaradas fuera del bloque principal)
function countSentences(t) {
return (t.match(/[.!?¡¿]+/g) || []).length || 1;
}
function countWords(t) {
return t.split(/\s+/).filter(Boolean).length;
}
function countSyllables(w) {
w = w.toLowerCase().normalize("NFD").replace(/[\u0300-\u036f]/g, "");
const syllableGroups = w.match(/[aeiouáéíóúü]{1,2}/g);
return syllableGroups ? syllableGroups.length : 1;
}
function totalSyllables(t) {
const words = t.split(/\s+/).filter(Boolean);
return words.reduce((acc, word) => acc + countSyllables(word), 0);
}
// Recoger todos los nodos que coincidan con el XPath
let snapshot = document.evaluate(xpath, document, null, XPathResult.ORDERED_NODE_SNAPSHOT_TYPE, null);
let combinedText = '';
for (let i = 0; i < snapshot.snapshotLength; i++) {
let node = snapshot.snapshotItem(i);
if (node && node.innerText) {
combinedText += node.innerText + ' ';
}
}
// Limpiar texto combinado
let text = combinedText
.replace(/\s+/g, ' ')
.replace(/^\s+|\s+$/g, '')
.trim();
if (text.length === 0) {
return seoSpider.data("XPath sin texto");
}
// Calcular valores base
let sentenceCount = countSentences(text);
let wordCount = countWords(text);
let syllableCount = totalSyllables(text);
// Calcular índice Flesch-Szigriszt original
// Fórmula: 206.835 - (62.3 × sílabas/palabras) - (palabras/oraciones)
let fleschSzigriszt = 206.835 - (62.3 * (syllableCount / wordCount)) - (wordCount / sentenceCount);
// Redondear
fleschSzigriszt = Math.round(fleschSzigriszt * 100) / 100;
// Devolver resultado
return seoSpider.data(fleschSzigriszt);
Este segundo código hace referencia a la fórmula simplificada
// Índice de Flesch-Szigriszt Simplificado + XPath...
let xpath = "//div[@class='left-column']//p";
function countSentences(t) {
return (t.match(/[.!?¡¿]+/g) || []).length || 1;
}
function countWords(t) {
return t.split(/\s+/).filter(Boolean).length;
}
function countSyllables(w) {
w = w.toLowerCase().normalize("NFD").replace(/[\u0300-\u036f]/g, "");
const syllableGroups = w.match(/[aeiouáéíóúü]{1,2}/g);
return syllableGroups ? syllableGroups.length : 1;
}
function totalSyllables(t) {
const words = t.split(/\s+/).filter(Boolean);
return words.reduce((acc, word) => acc + countSyllables(word), 0);
}
let snapshot = document.evaluate(xpath, document, null, XPathResult.ORDERED_NODE_SNAPSHOT_TYPE, null);
let combinedText = '';
for (let i = 0; i < snapshot.snapshotLength; i++) {
let node = snapshot.snapshotItem(i);
if (node && node.innerText) {
combinedText += node.innerText + ' ';
}
}
// Limpiar texto combinado
let text = combinedText
.replace(/\s+/g, ' ')
.replace(/^\s+|\s+$/g, '')
.trim();
if (text.length === 0) {
return seoSpider.data("XPath sin texto");
}
// Calcular índice de Flesch-Szigriszt
let sentenceCount = countSentences(text);
let wordCount = countWords(text);
let syllableCount = totalSyllables(text);
let syllablesPer100Words = (syllableCount / wordCount) * 100;
let wordsPerSentence = wordCount / sentenceCount;
let fleschSzigriszt = 206.84 - (0.60 * syllablesPer100Words) - (1.02 * wordsPerSentence);
fleschSzigriszt = Math.round(fleschSzigriszt * 100) / 100;
return seoSpider.data(fleschSzigriszt);
Del mismo modo, necesitamos nuestro «campo de seguridad» que nos sirva para validar el contenido extraido y ver si tiene sentido el índice de legibilidad calculado.
// Extrae el texto visible del xpath personalizado
let xpath = "//div[@class='left-column']//p";
// Busca todos los nodos que coincidan con el XPath
let snapshot = document.evaluate(xpath, document, null, XPathResult.ORDERED_NODE_SNAPSHOT_TYPE, null);
// Concatena el texto visible de todos los nodos encontrados
let combinedText = '';
for (let i = 0; i < snapshot.snapshotLength; i++) {
let node = snapshot.snapshotItem(i);
if (node && node.innerText) {
combinedText += node.innerText + ' ';
}
}
// Limpia el texto combinado
let cleanText = combinedText
.replace(/\s+/g, ' ') // Unifica espacios, saltos de línea, etc.
.replace(/^\s+|\s+$/g, '') // Elimina espacios al inicio y final
.trim();
// Devolver el resultado limpio o advertencia
if (cleanText.length > 0) {
return seoSpider.data(cleanText);
} else {
return seoSpider.data("No se encontró texto para el XPath especificado");
}
BONUS EXTRA: añade solo la valoración de legibilidad en base a la escala Inflesz
Al igual que Screaming Frog muestra un campo númerico de legibilidad y un campo adicional, con la escala de texto, también podemos replicar esto segundo, aplicando la escala Inflesz en base a la puntuación que obtenga cada texto. Podríamos configurar los snippet JS para el body completo:
// Índice de Flesch-Szigriszt Original - Escala Inflesz
function countSentences(text) {
return (text.match(/[.!?¡¿]+/g) || []).length || 1; // evitar división por 0
}
function countWords(text) {
return text.split(/\s+/).filter(Boolean).length;
}
function countSyllables(word) {
word = word.toLowerCase().normalize("NFD").replace(/[\u0300-\u036f]/g, ""); // quita tildes
const syllableGroups = word.match(/[aeiouáéíóúü]{1,2}/g);
return syllableGroups ? syllableGroups.length : 1;
}
function totalSyllables(text) {
const words = text.split(/\s+/).filter(Boolean);
return words.reduce((acc, word) => acc + countSyllables(word), 0);
}
function getInfleszScale(score) {
// Escala Inflesz basada en la investigación de Inés Mª Barrio Cantalejo
if (score < 40) return "Muy difícil";
if (score < 55) return "Algo difícil";
if (score < 65) return "Normal";
if (score < 80) return "Bastante fácil";
return "Muy fácil";
}
// Extraer y limpiar texto del body
let bodyText = document.body.innerText
.replace(/\s+/g, ' ')
.replace(/[\r\n\t]+/g, ' ')
.trim();
// Cálculos base
let sentenceCount = countSentences(bodyText);
let wordCount = countWords(bodyText);
let syllableCount = totalSyllables(bodyText);
// Fórmula original: 206.835 - (62.3 * (sílabas/palabras)) - (palabras/oraciones)
let fleschSzigriszt = 206.835 - (62.3 * (syllableCount / wordCount)) - (wordCount / sentenceCount);
// Redondear
fleschSzigriszt = Math.round(fleschSzigriszt * 100) / 100;
// Obtener la clasificación en la Escala Inflesz
let infleszGrade = getInfleszScale(fleschSzigriszt);
// Devolver solo la clasificación en texto (sin puntuación numérica)
return seoSpider.data(infleszGrade);Y para aplicar a un Xpath concreto:
// Índice de Flesch-Szigriszt Original Xpath - Escala Inflesz
let xpath = "//div[@class='left-column']//p";
// Funciones auxiliares (declaradas fuera del bloque principal)
function countSentences(t) {
return (t.match(/[.!?¡¿]+/g) || []).length || 1;
}
function countWords(t) {
return t.split(/\s+/).filter(Boolean).length;
}
function countSyllables(w) {
w = w.toLowerCase().normalize("NFD").replace(/[\u0300-\u036f]/g, "");
const syllableGroups = w.match(/[aeiouáéíóúü]{1,2}/g);
return syllableGroups ? syllableGroups.length : 1;
}
function totalSyllables(t) {
const words = t.split(/\s+/).filter(Boolean);
return words.reduce((acc, word) => acc + countSyllables(word), 0);
}
function getInfleszScale(score) {
// Escala Inflesz basada en la investigación de Inés Mª Barrio Cantalejo
if (score < 40) return "Muy difícil";
if (score < 55) return "Algo difícil";
if (score < 65) return "Normal";
if (score < 80) return "Bastante fácil";
return "Muy fácil";
}
// Recoger todos los nodos que coincidan con el XPath
let snapshot = document.evaluate(xpath, document, null, XPathResult.ORDERED_NODE_SNAPSHOT_TYPE, null);
let combinedText = '';
for (let i = 0; i < snapshot.snapshotLength; i++) {
let node = snapshot.snapshotItem(i);
if (node && node.innerText) {
combinedText += node.innerText + ' ';
}
}
// Limpiar texto combinado
let text = combinedText
.replace(/\s+/g, ' ')
.replace(/^\s+|\s+$/g, '')
.trim();
if (text.length === 0) {
return seoSpider.data("XPath sin texto");
}
// Calcular valores base
let sentenceCount = countSentences(text);
let wordCount = countWords(text);
let syllableCount = totalSyllables(text);
// Calcular índice Flesch-Szigriszt original
// Fórmula: 206.835 - (62.3 × sílabas/palabras) - (palabras/oraciones)
let fleschSzigriszt = 206.835 - (62.3 * (syllableCount / wordCount)) - (wordCount / sentenceCount);
// Redondear
fleschSzigriszt = Math.round(fleschSzigriszt * 100) / 100;
// Obtener la clasificación en la Escala Inflesz
let infleszGrade = getInfleszScale(fleschSzigriszt);
// Devolver solo la clasificación en texto (sin puntuación numérica)
return seoSpider.data(infleszGrade);Para todo lo mencionado basado en snippets JS merece la pena mencionar que Screaming Frog tiene un tutorial fantástico para identificar problemas que puede ser útil cuando no sepamos por qué no funcionan como esperamos (leelo por aquí: https://www.screamingfrog.co.uk/seo-spider/tutorials/how-to-debug-custom-javascript-snippets/)
Comparando resultados
Fórmula original vs fórmula simplificada
Si comparamos la fórmula original y la simplificada, en el método de contenido completo del <body>, nos encontramos con diferencias promedias de menos de 1,35 puntos.
Si comparamos la fórmula original y la simplificada, pero en esta ocasión con el método de contenido basado en un Xpath personalizado, nos encontramos con diferencias promedias de alrededor de 4 puntos. Este puede ser un dato más objetivo y realista, no obstante, las diferencias siguen siendo pequeñas entre métodos, aunque podría tener impacto en la escala que evalúa las puntuaciones.
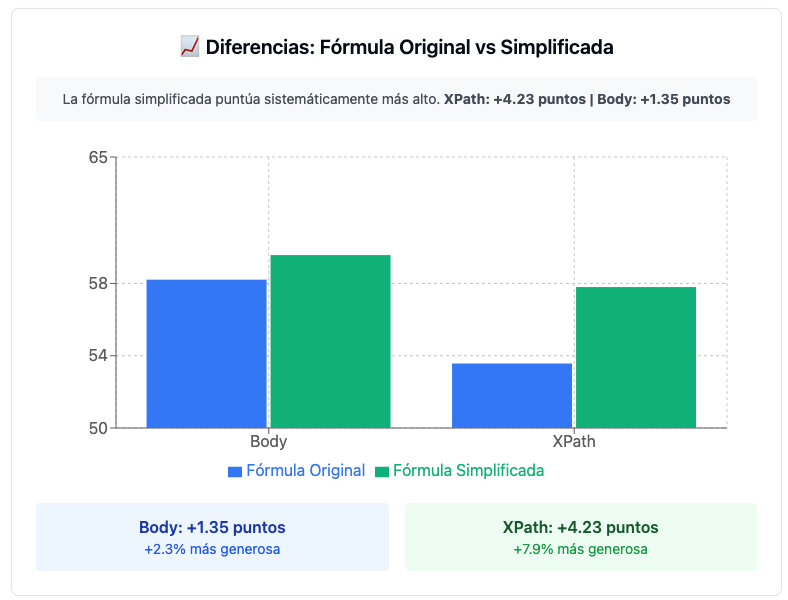
Body vs Xpath
No he querido hacer comentarios al respecto de usar todo el contenido del <body> o usar solo un fragmento de contenido basado en Xpath, no quiero generalizar si una es mejor o peor. La cuestión aquí es que cada proyecto es un mundo y quería dar dos opciones para que sea más accionable.
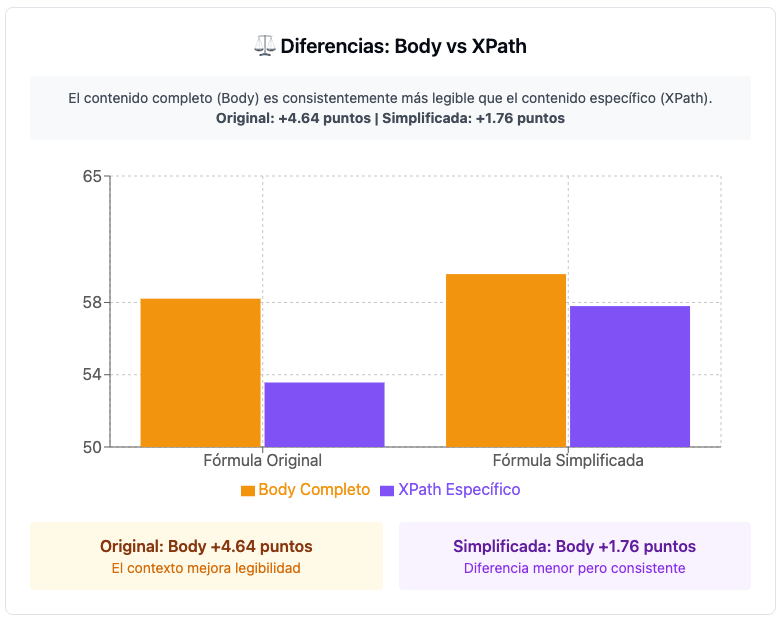
Los resultados muestran que el contenido completo del <body> es consistentemente más legible que el contenido específico basado en XPath ya que se ve influenciado por los elementos adicionales como navegación, menús y contexto mejoran la puntuación de legibilidad.
Merece la pena tener en cuenta que elegir una fórmula u otra, además de aplicarlo en el <body> o usar un Xpath concreto, puede suponer cambios relevantes en la escala final de cara a interpretar los resultados.
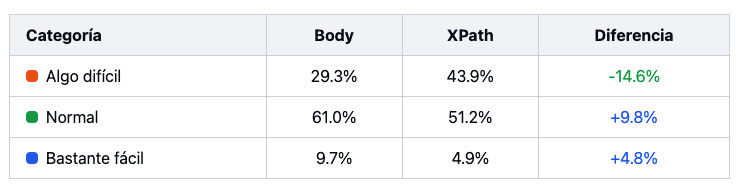
El análisis más concreto usando Xpath nos lleva a tener casi un 15% más de contenidos difíciles que si mirásemos el <body>, algo nada desdeñable, por otro lado.
Flesch Reading Ease (en) vs Flesch-Szigriszt (es)
A pesar de no ser comparables, las fórmulas españolas puntúan 12-13 puntos MÁS ALTO que Flesch Reading Ease, esto no es bueno ni malo, cada fórmula trata de adaptarse a las idiosincrasias de cada idioma y particularidades del lenguaje.
Esto reafirma la necesidad de contar métricas específicas para cada idioma de cara a tener una idea aproximada de la legibilidad real de un texto concreto o una url completa y evitar incurrir en errores de análisis e interpretación.
Conclusiones, limitaciones y siguientes paso
La legibilidad es un factor importante como antesala a analizar la calidad de contenido de una web. El comportamiento de los usuarios puede verse altamente influenciado en base no solo a diseño, fiabilidad, conocimiento de marca….también por la forma de redactar y escribir los contenidos.
La temática del proyecto también juega un papel fundamental junto con el nivel de conocimiento de los usuarios objetivo, con esto en mente, es crucial adaptar el contenido y hacerlo lo más legible posible como puerta de entrada a la retención y fidelización: ¡si le gustamos, no se irán, si le encantamos, volverán!
La metodología empleada está basada en estudios de expertos y en la literatura disponible para el idioma español, que puede que incluya otros modelos o referencias, pero se ha optado por usar aquellos más notorios o más consolidados.
Queda ampliamente demostrado que necesitamos métricas específicas por idioma para poder analizar y medir de la mejor manera la legibilidad de los textos
También a considerar que los códigos presentados pueden tener ciertas limitaciones para casuísticas más especiales que pueden quedar fuera de los casos de uso contemplados aquí. A pesar de ello, el código ha sido revisado y validado por Alfonso Moure, experto SEO y programador de formación, se aceptan comentarios de mejora :)
Si te surgen formas de expandir esto a otros casos estaré encantada de leerte en comentarios y poder cooperar en lo posible.
Recursos y bibliografía
Szigriszt Pazos, P. (1993). SISTEMAS PREDICTIVOS DE LEGIBILIDAD DEL MENSAJE ESCRITO: FORMULA DE PERSPICUIDAD. Universidad Complutense de Madrid.
Ver tesis completa (PDF)
Carreras, O. (2016, octubre). Medición de la readability o comprensión de los textos en español. Estado actual y retos. Usable y accesible. https://olgacarreras.blogspot.com/2016/10/medicion-de-la-readability-o.html
Screaming Frog. (2022). How to test readability. Screaming Frog. https://www.screamingfrog.co.uk/seo-spider/tutorials/how-to-test-readability/
Soy MJ Cachón
Consultora SEO desde 2008, directora de la agencia SEO Laika. Volcada en unir el análisis de datos y el SEO estratégico, con business intelligence usando R, Screaming Frog, SISTRIX, Sitebulb y otras fuentes de datos. Mi filosofía: aprender y compartir.
Explorar por temas
tal vez sea
de tu interés
-

LaLiga al revés: ¿Y si en vez de equipos compitiesen las marcas y patrocinadores?
Si nos fijáramos en las marcas y patrocinadores de cada equipo de LaLiga, ¿quién ganaría? ¿quién metería más goles? ¿quién sería más expulsado? Le damos la vuelta a los datos para encontrar nuevos ángulos
Leer artículo -
Cómo fusionar ficheros excel con r
En este post quiero compartir un pequeño y simple script que ayuda a fusionar todos los excel descargados, eliminar filas de keywords sin volumen, ordenar los datos de mayor a menor volumen y poner un 0 en aquellos campos de volumen estacional que vengan vacíos. ¡Vamos a explicarlo paso a paso!
Leer artículo -
Tip SEO: automatizar tareas
De forma muy breve, voy a dar un consejo para automatizar, en cierta medida, la creación de bases de datos de bloggers o contactos, que en ocasiones pueden precisar las estrategias de Link Building de nuestros proyectos SEO. Para poder llevar a cabo el proceso es necesario lo siguiente: – Link Building Query Builder: en … Tip SEO: automatizar tareas
Leer artículo