

En nuestros análisis SEO muchas veces requerimos de extraer fechas para luego hacer agrupaciones en base a las mismas y entender la evolución de aquello que estemos analizando.
Un ejemplo muy habitual puede ser saber la fecha de publiciación o modificación de contenidos, para luego poner en contraposición métricas de tráfico, extensión de contenidos, enlaces internos o externos…
Qué utilidad tiene saber la fecha de publicación y actualización
Dependiendo en el área SEO que nos movamos, o si no somos SEOs, en qué rol nos manejamos dentro de todas las capas de captación orgánica y su incidencia en las estrategias digitales. En general hablamos de contenido, pudiendo tener distintas vertientes
- Webs puras de contenido
- Webs de noticias
- Webs que tienen hubs de contenido (blog, academia, guías, soporte….)
Esos tipos de webs luego pueden generar muchos patrones que son analizables:
- Entender la tasa de actualización de los contenidos de un sitio
- Cruzar datos de fecha con indexabilidad y rastreabilidad
- Cruzar datos de fecha con autoría
- Cruzar artículos por frecuencia de actualización con frecuencia de tráfico
Son solo algunos ejemplos que nos pueden brindar muchos insights adaptados a la naturaleza de cada proyecto.
Qué consideramos fecha de publicación y actualización
Mejor que yo lo explican en Marfeel en este artículo: https://community.marfeel.com/t/how-does-marfeel-detect-the-publication-and-last-update-date-of-an-article/36371
Me ha parecido muy clarito y por eso me voy a basar en sus ejemplos para hacer mi aproximación con distintos métodos, siempre basado en marcado Schema de distinto formato.
De hecho, como profesionales del análisis SEO, tenemos que encontrar la vía homogénea de llegar a esos datos y que cubran la mayoría de los casos, es por eso que en este artículo no voy a hablar de la fecha que figura en el HTML visible de una web, ya que cada web, usará una forma diferente de etiquetar la fecha y en algunos casos, incluso, ni la mostrarán.
Vamos con los tipos y los métodos para cada uno
#1 Extraer fechas del marcado JSON+LD
Tal y como indica el artículo de Marfeel mantengo el mismo ejemplo de código de muestra:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "NewsArticle",
"datePublished": "2021-08-01T04:30:00Z",
"dateModified": "2021-08-01T05:30:00Z"
}
</script>Para este tipo de casuísticas, varios métodos:
Método 1: expresiones regulares sueltas para tu scraper favorito (Screaming Frog, Sitebulb, etc.)
"datePublished":"([^"]*)""dateModified":"([^"]*)"Método 2: lenguaje R para integrar en tus script
# Librerías base
# install.packages("httr") # si no lo tienes instalado
library(httr)
# URL ficticia
url <- "https://example.com/ejemplo1.html"
# Obtener el contenido como texto
resp <- GET(url)
html_text <- content(resp, "text", encoding = "UTF-8")
# Expresiones regulares
date_published <- sub('.*"datePublished":"([^"]*)",.*', '\\1', html_text)
date_modified <- sub('.*"dateModified":"([^"]*)".*', '\\1', html_text)
cat("datePublished:", date_published, "\n")
cat("dateModified:", date_modified, "\n")Esto solo es la base de código que luego nos permite añadir esos valores a un dataframe y trabajar con más datos, pero para mostrar el resultado, adjunto la salida por consola:

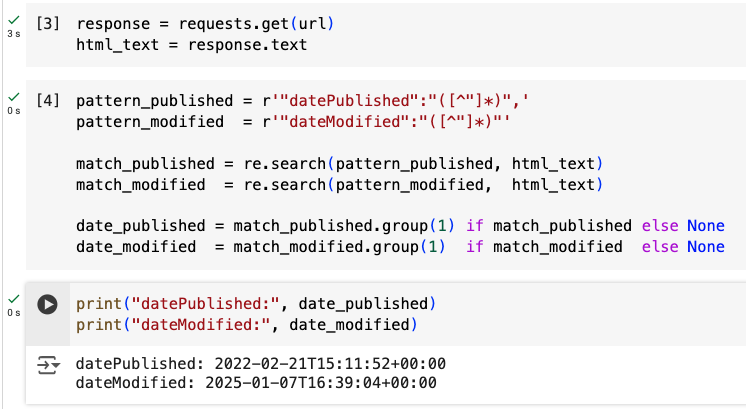
Método 3: lenguaje Python para integrar en tus script
import requests
import re
url = "https://example.com/ejemplo1.html"
response = requests.get(url)
html_text = response.text
pattern_published = r'"datePublished":"([^"]*)",'
pattern_modified = r'"dateModified":"([^"]*)"'
match_published = re.search(pattern_published, html_text)
match_modified = re.search(pattern_modified, html_text)
date_published = match_published.group(1) if match_published else None
date_modified = match_modified.group(1) if match_modified else None
print("datePublished:", date_published)
print("dateModified:", date_modified)Tal y como decía con el código de R, esto es una aproximación sencilla pero la potencia de usar programación es integrarlo en los análisis de datos, dejo de forma simbólica el aspecto del print, usando la misma url que en el caso anterior, ahora usando Google Colab.
#2 Extraer fechas de la meta item property
Ejemplo de código de muestra:
<head>
<meta property="article:published_time" content="2025-01-02T12:00:00Z" />
</head>Método 1: expresión xpath
//meta[@property="article:published_time"]/@contentLa gran versatilidad de Xpath nos permite, si queremos, hacer transformaciones a los valores antes de que sean devueltos.
Por ejemplo, si solo queremos el año:
substring-before(//meta[@property="article:published_time"]/@content, "-")Por ejemplo, si solo queremos la fecha sin la hora:
substring-before(//meta[@property="article:published_time"]/@content, "T")O por ejemplo, si queremos cambiar guiones por barras
translate(substring-before(//meta[@property="article:published_time"]/@content, "T"), "-", "/")Método 2: expresión regular
La expresión más sencilla siempre que la etiqueta sea tal cual se muestra será más que suficiente
<meta property="article:published_time" content="([^"]*)"Pero si nos encontramos con atributos adicionales por medio o saltos de línea, podría no funcionar, para lo cual se presenta una algo más robusta:
<meta\s+[^>]*property="article:published_time"\s+[^>]*content="([^"]+)"Método 3: lenguaje R
# install.packages("rvest") # si no lo tienes instalado
library(rvest)
url <- "https://example.com/ejemplo2.html"
page <- read_html(url)
date_published <- page %>%
html_node('meta[property="article:published_time"]') %>%
html_attr("content")
cat("datePublished:", date_published, "\n")Método 4: lenguaje Python
import requests
from lxml import html
url = "https://example.com/ejemplo2.html"
response = requests.get(url)
tree = html.fromstring(response.content)
# Xpath para extraer el atributo content
date_published = tree.xpath('//meta[@property="article:published_time"]/@content')
date_published = date_published[0] if date_published else None
print("datePublished:", date_published)#3 Extraer fechas del time item property (atributo datetime)
Ejemplo de código de muestra:
<time itemprop="datePublished" datetime="2025-01-03T13:00:00Z">3 de enero de 2025</time>Método 1: expresión xpath
//time[@itemprop="datePublished"]/@datetimeMétodo 2: expresión regular
Expresión más básica y sencilla:
<time itemprop="datePublished" datetime="([^"]*)">Expresión algo más robusta:
<time\s+[^>]*itemprop="datePublished"[^>]*datetime="([^"]*)"Método 3: lenguaje R
# install.packages("rvest") # si no lo tienes instalado
library(rvest)
# URL ficticia con un <time itemprop="datePublished" datetime="...">
url <- "https://example.com/ejemplo2.html"
# Leemos y parseamos la página
page <- read_html(url)
# Extraer la fecha-hora completa del atributo datetime
published_time <- page %>%
html_node(xpath = '//time[@itemprop="datePublished"]') %>%
html_attr("datetime")
cat("Fecha completa: ", published_time, "\n")Método 4: lenguaje Python
import requests
from lxml import html
# URL ficticia con un <time itemprop="datePublished" datetime="...">
url = "https://example.com/ejemplo2.html"
# Descargamos la página
response = requests.get(url)
tree = html.fromstring(response.content)
# Extraer la fecha-hora completa usando Xpath
date_times = tree.xpath('//time[@itemprop="datePublished"]/@datetime')
published_time = date_times[0] if date_times else None
print("Fecha completa:", published_time)#4 Extraer fechas del time item property (atributo content)
Ejemplo de código de muestra:
<time itemprop="datePublished" content="2025-01-05T14:00:00Z">
5 de enero de 2025
</time>Método 1: expresión xpath
//time[@itemprop="datePublished"]/@contentSi quiero la fecha SIN la hora, también es fácil de manipular el valor antes de extraerlo:
substring-before(//time[@itemprop="datePublished"]/@content, 'T')Método 2: expresión regular
<time[^>]*itemprop="datePublished"[^>]*content="([^"]*)"Método 3: lenguaje R
# install.packages("rvest") # si no lo tienes
library(rvest)
# URL ficticia
url <- "https://example.com/ejemplo2.html"
# Leer y parsear la página
page <- read_html(url)
# Extraer la fecha-hora completa
published_time <- page %>%
html_node(xpath = '//time[@itemprop="datePublished"]') %>%
html_attr("content")
cat("Fecha completa:", published_time, "\n")Método 4: lenguaje Python
import requests
from lxml import html
url = "https://example.com/ejemplo2.html"
response = requests.get(url)
tree = html.fromstring(response.content)
# Extraer la fecha-hora completa del atributo 'content'
date_times = tree.xpath('//time[@itemprop="datePublished"]/@content')
published_time = date_times[0] if date_times else None
print("Fecha completa:", published_time)#5 Extraer fechas del time item property (nodo texto)
Ejemplo o muestra del código:
<time itemprop="datePublished">2025-01-05T09:00Z</time>Método 1: expresión xpath
//time[@itemprop="datePublished"]/text()Método 2: expresión regular
<time[^>]*itemprop="datePublished"[^>]*>([^<]+)</time>Método 3: lenguaje R
# install.packages("rvest") # si no lo tienes
library(rvest)
url <- "https://example.com/ejemplo2.html"
page <- read_html(url)
# Extraer el texto completo
published_time <- page %>%
html_node(xpath = '//time[@itemprop="datePublished"]') %>%
html_text(trim = TRUE)
cat("Contenido completo:", published_time, "\n")
# Ej: "2025-01-05T09:00Z"Método 4: lenguaje Python
import requests
from lxml import html
url = "https://example.com/ejemplo2.html"
response = requests.get(url)
tree = html.fromstring(response.content)
# Extraer el texto dentro de <time itemprop="datePublished">
time_text_list = tree.xpath('//time[@itemprop="datePublished"]/text()')
published_time = time_text_list[0].strip() if time_text_list else None
print("Contenido completo:", published_time)
# Ej: 2025-01-05T09:00Z#6 Extraer fechas de la meta article type
Muestra de código para los ejemplos:
<meta property="article:published_time" content="2024-08-01T17:41:45+00:00" />Método 1: expresión xpath
//meta[@property="article:published_time"]/@contentMétodo 2: expresión regular
<meta[^>]*property="article:published_time"[^>]*content="([^"]*)"Método 3: lenguaje R
# install.packages("rvest") # si no lo tienes
library(rvest)
url <- "https://example.com/ejemplo2.html"
page <- read_html(url)
# Extraer fecha completa (por ejemplo, 2024-08-01T17:41:45+00:00)
published_time <- page %>%
html_node('meta[property="article:published_time"]') %>%
html_attr("content")
cat("Fecha completa:", published_time, "\n")Método 4: lenguaje Python
import requests
from lxml import html
url = "https://example.com/ejemplo2.html"
response = requests.get(url)
tree = html.fromstring(response.content)
# Extraer la fecha completa
date_time_list = tree.xpath('//meta[@property="article:published_time"]/@content')
published_time = date_time_list[0] if date_time_list else None
print("Fecha completa:", published_time)Y con esto, creo que tenemos ya un abanico completo para poder abordar la extracción de fechas de cara a análisis SEO que impliquen fechas de publicación y actualización.
Siguientes pasos
Puedes usar esta metodología sencilla antes de embarcarte a extraer los datos:
- Observar cómo está construido el html del que vas a extraer los datos para ver casuísticas en las que se presenta el código antes de crear las expresiones o el código de extracción
- Definir qué elementos quieres extraer y si requieren de manipulación o transformación
- Hacer pruebas previas para validar que el método de extracción funciona correctamente
- Decidir qué herramienta usar
- Lanzar e integrar en la lógica de datos del proyecto
A partir de aquí, se puede ir iterando y mejorando el proceso en cada caso, incluso hasta el punto de automatizar todo o parte del proceso, lanzando los análisis periódicamente.
Espero que pueda ser útil el artículo y si es así, compártelo y que llegue a más gente
¡Hasta la próxima!
Soy MJ Cachón
Consultora SEO desde 2008, directora de la agencia SEO Laika. Volcada en unir el análisis de datos y el SEO estratégico, con business intelligence usando R, Screaming Frog, SISTRIX, Sitebulb y otras fuentes de datos. Mi filosofía: aprender y compartir.
Explorar por temas
tal vez sea
de tu interés
-

Análisis de competencia SEO usando estadística: mi TFM de Estadística Aplicada con R
Acabo de terminar mi Trabajo de Fin de Máster del Máster de Estadística con R de Máxima Formación junto a la Universidad Nebrija (gracias Rosana Ferrero por el apoyo y seguimiento durante el máster) y quería compartir un resumen de lo que he hecho, porque creo que puede ser útil para quienes trabajan en SEO … Análisis de competencia SEO usando estadística: mi TFM de Estadística Aplicada con R
Leer artículo -
Trucos y Tips para Excel
Hoy traemos un post con trucos y tips de utilidad para Excel, que se puede aplicar en el día a día a distintas áreas de marketing online, no descubro nada ni siquiera es algo que se pueda considerar «avanzado».
Leer artículo -
¿Quién ha ganado la Eurocopa en Google? Visibilidad, popularidad y otros datos
La Eurocopa 2024 ha durado un mes y ya tiene ganador: ¡España! Pero…. ¿se repite el patrón si nos fijamos en quiénes han sido los jugadores y selecciones que más búsquedas han acumulado en Google, antes y durtante la Eurocopa? GANADORES DE LA EUROCOPA EN GOOGLE POSICIONAMIENTO EN GOOGLE DE LAS WEBS DE LAS SELECCIONES … ¿Quién ha ganado la Eurocopa en Google? Visibilidad, popularidad y otros datos
Leer artículo