

Si el día 1 fue ciencia y el día 2 fue psicología, el día 3 fue ecosistema. Y la palabra resume bien lo que pasó en eel escenario, que el SEO ya no es un canal, es una red distribuida con distintas superficies (Google, Discover, Reddit, YouTube, TikTok, ChatGPT, Perplexity, Gemini) en la que tu marca aparece, se cita, se ignora o se sustituye dependiendo de cómo la describan otros, además de cómo lo hagas tú.
Lla era de los «10 enlaces azules» no vuelve, las métricas viejas mienten y quien siga vendiendo tráfico en lugar de negocio está jugando el partido del año pasado.
Este es el resumen del día 3, primero las 5 ideas que lo unen y después charla a charla, en el orden de la agenda.
TL;DR — Las 5 ideas que unen el segundo día de #SEOWeek 2026
- El SEO ya no es un canal, es un ecosistema. El 85% de las menciones de marca en respuestas de IA viene de terceros: Reddit, YouTube, reseñas, foros y prensa. Y solo el 12% de los resultados se solapa entre Google y ChatGPT. Si optimizas únicamente tu dominio, eres invisible para la mitad del mercado. La pelea ya no es por rankear, es por estar presente en todas las superficies donde se forma la respuesta antes de que el usuario llegue (o no) a ti.
- De rankings a citaciones, memoria y centralidad. Las métricas que llevamos años vendiendo (posiciones, clics, DR) ya no explican el negocio. Las que sí lo explican son cuota de voz en LLMs, tasa de citación, sentimiento de la mención, presencia en Common Crawl, centralidad armónica y similitud de coseno. La pregunta deja de ser «¿salgo en Google?» para convertirse en «¿soy yo la respuesta cuando la IA contesta?«.
- Distribución por encima de creación, distinción por encima de volumen. El contenido genérico generado con IA («AI slop») está siendo penalizado y arrastra al resto del sitio. Lo que sí funciona es lo opuesto: experiencia real, datos propietarios, hiper-localización, opinión de primera mano y, sobre todo, distribuir esa evidencia de forma masiva fuera de tu web para entrenar el consenso de los modelos. Crear una vez, distribuir para siempre.
- El ingeniero de relevancia sustituye al SEO técnico clásico. Embeddings, clustering, similitud de coseno, densidad de entidades, ganancia de información, schema avanzado con 80+ entidades, llms.txt, WebMCP, agentes que se conectan a tus herramientas. El nuevo perfil mezcla NLP, machine learning y estrategia de negocio. Quien siga «prompteando» tareas sueltas en lugar de construir sistemas escalables, se queda fuera.
- Vende negocio, no tráfico (y prepárate para 2027). Si tu reporte sigue centrado en impresiones y clics, tus clientes te van a despedir cuando Google cambie de UI (y va a cambiar). Toca conectar el SEO con ingresos, conversiones y miedos reales del cliente. Y prepararse para un escenario donde, según los ponentes, el tráfico de bots superará al humano en toda la web hacia 2027, lo que rompe definitivamente las líneas base históricas.
Las 10 charlas del tercer día de #SEOWeek 2026, una a una
21 Ross Simmonds
Ponente: Ross Simmonds, Foundation Marketing
Charla: Inception: How to Plant Your Brand Into the Memory Layer of Every LLM
Ross arrancó el día con un golpe de mesa muy parecido al que dio Will Reynolds el día 2: los 10 enlaces azules no van a volver y Google ya es un destino final, no un puente hacia tu sitio. Pero su tesis va un paso más allá y es que las marcas tienen una ventana muy corta para «plantarse» en la memoria de los LLMs antes de que esa memoria se consolide en los próximos 48 meses.
La fórmula que propone tiene tres palancas.
- La primera es E-E-A-T en serio, no como casilla, ya que los LLMs necesitan evidencia para fundamentar respuestas y modelos como Gemini siguen usando los backlinks como señal de autoridad.
- La segunda es contenido off-site, porque el 85% de las menciones de marca en búsquedas de IA vienen de terceros, especialmente Reddit (que domina el long-tail y los listados «mejores X») y YouTube (mejor ROI del mercado y dominio absoluto en los AI Overviews de Google).
- La tercera es mentalidad de inversor, esto es, distribuir antes que crear, multiplicar el área de superficie con variantes hiper-localizadas y dejar de obsesionarse con PDFs corporativos que nadie lee.
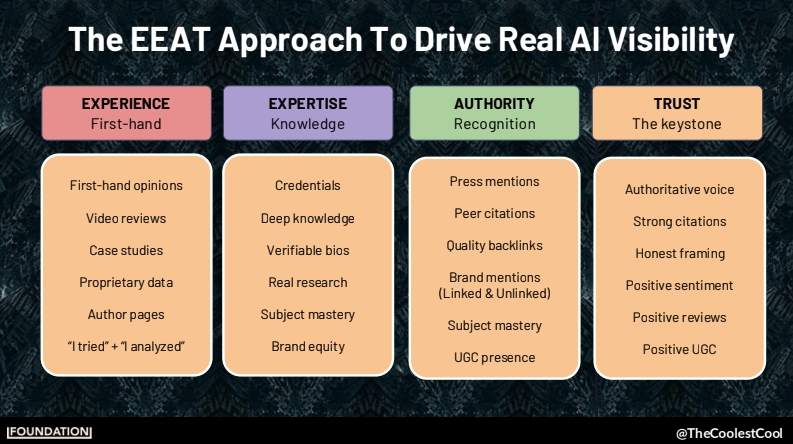
Cerró con un mensaje incómodo: necesitamos un «juramento hipocrático» colectivo para no manipular engañosamente la memoria de los modelos, porque lo que hagamos hoy se va a quedar entrenando cultura durante décadas.
La frase: «Si eres un CMO en 2026 y todavía estás obsesionado con los rankings de SEO, estás jugando el juego de la década pasada.«
Sigue al autor:
https://x.com/thecoolestcool
https://www.linkedin.com/in/rosssimmonds
22. Carrie Rose
Ponente: Carrie Rose, Rise at Seven
Charla: 7 small creative changes that lead to BIG discovery wins
Carrie defendió que los grandes saltos vienen de cambios de un grado, esto es, pequeños ajustes estratégicos que rompen los silos entre SEO, PR, redes sociales y marca y que se acumulan en el tiempo.
Su gran reencuadre conceptual es que la barra de búsqueda es la mejor ventana al comportamiento humano que existe y, por tanto, el equipo de SEO debería ser el proveedor central de insights para toda la empresa, no un departamento técnico que vive en su silo.
Dejó datos potentes para defender estos:
- el viaje de compra implica hasta 97 interacciones a lo largo de 10 semanas, consultando una media de 3,6 plataformas
- Google está integrando entre 35 y 50 nuevas características en SERPs (resúmenes de IA, vídeos cortos, foros) que dictan qué formatos hay que producir.

Introdujo dos conceptos prácticos.
- La ingeniería de PR digital para LLMs: cómo te describes en notas de prensa determina cómo te categorizan los modelos y, además, la proximidad de la palabra clave al backlink (5-8 palabras) mejora rankings de forma medible.
- Y el «contenido de búsqueda social», que no es contenido social rápido y reactivo, sino contenido lento y perenne que ataca puntos de dolor reales y resuelve problemas concretos.
Cerró con el caso «jeans rosas de Zara» de 2021 para ilustrar por qué hay que hacer ingeniería inversa con influencers: solo generar demanda con creadores sobre productos donde ya rankeas en orgánico, o regalas las ventas a la competencia.

La frase: «El contenido social atiende al interés. El contenido de búsqueda social atiende a la intención.«
Sigue a la autora:
https://x.com/carrierosesays
https://www.linkedin.com/in/carrierose
23. Brie Moreau
Ponente: Brie Moreau, WLDNA
Charla: Inside the LLM Black Box: How to Gain AI Visibility
La charla más matemática del día, hilo directo con lo que Andrea Volpini y Mike King plantearon en el día 1. Brie llegó con conclusiones de más de 2.000 horas de investigación y 11 millones de citaciones de IA analizadas y desarmó en directo la ilusión de personalización de ChatGPT, ya que ante la misma pregunta sobre hoteles en Hawái, la sala entera recibió los mismos dos resultados. La supuesta personalización es, en muchos casos, un patrón explotable.
Su mensaje técnico se apoya en cuatro ideas.
- Common Crawl es la base de entrenamiento de todos los grandes LLMs, así que si tu sitio no está indexado ahí, eres invisible para la IA por mucho que rankees en Google (de hecho, solo el 12% de los resultados se solapa entre Google y ChatGPT).
- Centralidad armónica supera a Domain Rating, con la analogía de aeropuertos como argumento: París es famoso (DR alto) pero Frankfurt es el verdadero hub de conexiones, hay que identificar y conectar con los hubs reales del nicho.
- Vectorización en 768 dimensiones y similitud de coseno: hay un punto óptimo matemático en títulos y contenido que correlaciona con ser citado.
- Y «semisticles» (listicles semánticos diseñados para enlazar las mismas fuentes que ya leen los nodos de autoridad) como táctica para adherirse a la red de autoridad de los LLMs.

Aportó además un dato escalofriante para los que dudan del peso real del contenido en LLMs. Un experimento de Anthropic demostró que bastaron 250 documentos estratégicamente colocados para convencer a un modelo de que la Torre Eiffel estaba en otra ciudad. La manipulación de nodos no es teoría, es una palanca real.
La frase: «Debes dejar de pensar en DR y PageRank, y empezar a pensar en centralidad armónica. Esa es la salsa secreta.«
Sigue al autor:
https://www.linkedin.com/in/briemoreau
24. Ray Martínez
Ponente: Ray Martínez, Archer Education
Charla: Watch the Party Die: Engineering «Answerability» for Prospective Students
Ray contó una historia de caída y reconstrucción que cualquiera del sector educativo (y muchos del SaaS) pueden firmar. Tras años de «fiesta» con SEO tradicional en educación superior, el tráfico se desplomó en cuestión de meses, ya que el 70% de los estudiantes potenciales utiliza ya la IA antes de visitar la web institucional, y los CTR orgánicos cayeron un 25% interanual.
Parte del problema fue puramente técnico (etiquetas <article> mal colocadas que bloqueaban a los crawlers de LLM), pero el diagnóstico real es estratégico, es decir, el SEO clásico ya no basta como capa única.
Su respuesta es la metodología AROS (AI-Ready Organic Strategy), que unifica SEO, social, contenido y PR bajo el mismo paraguas. Construyeron un schema JSON-LD ultra personalizado con más de 85 entidades de datos (acreditaciones, resultados de empleabilidad, datos del profesorado, costes, resultados por programa) para «educar» directamente a los LLMs sobre el valor real de sus programas, en lugar de esperar a que la IA dedujese ese valor de fuentes de terceros.
Lo combinaron con liderazgo de pensamiento académico real (decanos y profesores firmando en publicaciones top) y con herramientas internas que cruzan APIs de LLM con Screaming Frog para auditar y automatizar.
El subtexto de la charla es importante porque estamos en una ventana corta de «red abierta», los modelos están aprendiendo a marchas forzadas y quien no construya ahora lo va a tener mucho más difícil cuando se cierre.
Ray también soltó una idea polémica para muchos de los presentes, que es probar archivos como llms.txt y servir contenido en Markdown para facilitar la lectura a los bots.
La frase: «Sigue construyendo, porque la construcción será lo que te salve.«
Sigue al autor:
https://www.linkedin.com/in/raymartinezseo
25. Angela Skane
Ponente: Angela Skane, Network Solutions
Charla: What TikTok Shop Can Teach SEOs About Content That’s Seen and Converts
Angela recogió el guante que dejó Azeem Ahmad el día 2 sobre comportamiento del consumidor y la llevó al terreno operativo del SEO.
Su tesis es directa: el 95% de las decisiones de compra ocurren a nivel subconsciente, los creadores de TikTok llevan años aplicando esto sin pedir permiso a nadie, y los SEOs seguimos optimizando para robots como si los humanos del otro lado fueran tablas de keywords con piernas.

Adaptó la fórmula de TikTok al contenido escrito en una estructura repetible: gancho visual (imágenes o vídeos incrustados en los primeros segundos del scroll) + storytelling + palancas psicológicas + testing continuo.
Y detalló las 8 palancas psicológicas que funcionan en cualquier vertical:
- cuidado y protección de los seres queridos
- supervivencia y disfrute de la vida
- comida y bebida
- evasión del miedo y el dolor
- compañía sexual
- condiciones de vida cómodas
- superioridad o éxito sobre otros
- aprobación social.
La idea es identificar cuál de estas palancas activa cada pieza y mapearla deliberadamente al user journey.
Los resultados que mostró cierran el argumento sin discusión, ya que aplicando este enfoque entre julio de 2025 y marzo de 2026, su equipo logró un +136% en visitas al blog, un +286% en volumen de pedidos, y unos 600 artículos en primera página, sin link building tradicional.
Es decir, ganaron por entender mejor a las personas, no por meter más enlaces.
La frase: «El futuro de la búsqueda no lo ganará el contenido más optimizado, lo ganará el contenido que mejor entienda a las personas.«
Sigue a la autora:
https://www.linkedin.com/in/angelaskane
26. Sam Torres
Ponente: Sam Torres, «SEO Mermaid»
Charla: Your Competitors Are Still Prompting. You Could Be Building
Sam atacó frontalmente la dependencia de los LLMs como atajo y recogió el guante de Mike King y Noah Learner del día 1, esto es, deja de promptear tareas sueltas y empieza a construir sistemas.
Su propuesta es un marco híbrido ML + LLM en tres pasos que devuelve consistencia matemática a un terreno donde la IA generativa da resultados distintos cada vez que la consultas.
- El paso uno es embeddings: convertir el contenido en vectores matemáticos, esto es, traducir palabras a matemáticas.
- El paso dos es clustering: agrupar esos vectores en «vecindarios» semánticos reales que superan la simple coincidencia de keywords.
- Y el paso tres son los LLMs, pero solo al final, para etiquetar clusters, dar narrativa, encontrar gaps y hacer que el output sea presentable y accionable.
Lo importante es el orden, ya que primero va la matemática (reproducible y revisada académicamente) y luego va el lenguaje (caja negra inconsistente).

Sam compartió cuadernos en tres niveles según presupuesto y madurez, y son Rising Tide (sin coste de API, ideal para empezar), Open Water (con API keys, para producción ligera) y Deep Sea (para empresas con flujos a gran escala).
Aplicaciones inmediatas que mostró:
- gap analysis evolucionado (que no devuelve listas planas de keywords sino amplitud y profundidad temática real)
- enlazado interno automatizado por proximidad semántica, no por reglas manuales.
Sus dos mantras del cierre:
- la regla 80/20 (la perfección es el enemigo de la automatización, conformarse con 80% libera tiempo brutal)
- dirige y delega a la IA como a un becario (el simple ejercicio de listar todos los pasos de la tarea ya te enseña que es más compleja de lo que pensabas).
La frase: «Es en cómo escalamos donde generalmente empezamos a fallar.«
Sigue a la autora:
https://x.com/seomermaid
https://www.linkedin.com/in/samtorres
27. Brian Cosgrove
Ponente: Brian Cosgrove (Braindew)
Charla: Deception, Distinction, and Directives
Brian estructuró la charla en tres actos y los tres son directos.
- Engaño. Las herramientas analíticas que usamos a diario (GA4, Adobe, Amplitude) están perdiendo precisión a una velocidad que la mayoría no quiere admitir, esto es por bloqueadores de tracking, proxies de operadores móviles, IPs compartidas, comportamiento guiado por IA y atribución rota. Las líneas base históricas interanuales ya no son fiables y el aviso es serio porque para 2027, el tráfico no humano (bots, agentes, asistentes de IA) superará al humano en toda la web. Hay que implementar CDNs (Cloudflare), antifraude, etiquetado server-side y «datos de origen funcionales» (donde la recogida está vinculada al funcionamiento del sitio, no al consentimiento marketing).
- Distinción. Parar de buscar relevancia genérica y elegir «10 carriles» específicos donde se pueda ganar de verdad. Sustanciar esas afirmaciones con evidencia objetiva, no con copy de marketing. Su caso favorito es la marca de equipaje Away, que en lugar de afirmar que sus maletas cabían en cabina, las midió físicamente en los medidores de JFK, Newark y LaGuardia, lo documentó y difundió. Ese es el nivel de evidencia que los LLMs premian.
- Directivas. El futuro es «AI First» como hace 10 años fue «Mobile First». Los agentes de IA actuales navegan webs visuales como un robot aspirador atascado en una esquina, así que hay que diseñar modos para agentes (rutas transaccionales claras, sin diseño gráfico complejo, con protocolos como WebMCP) para que puedan ejecutar tareas sin pelearse con tu hero section.

La frase: «Deja de intentar escribir la respuesta. Concéntrate en ser la respuesta.«
Sigue al autor:
https://www.linkedin.com/in/briancosgrove
28. John Shehata
Ponente: John Shehata
Charla: The Truth About Google Discover: What Works, What Doesn’t, and What’s Changing
Si hay una charla del día que va a recortar y guardar todo el sector editorial, es esta. John llegó con datos de millones de artículos y billones de impresiones y arrancó con datos increibles:
- Google Discover ya representa el 75% del tráfico de Google, mientras la búsqueda tradicional ha caído al 23%.
- El CTR de Discover es seis veces superior al de Search por ser un feed inmersivo, sin distracciones laterales y con menos competencia visual.
La trampa es que Discover no es gratis y depende totalmente de Search, ya que para sobrevivir en el feed hay que rendir bien primero en búsqueda tradicional, sostenidamente, y con interacciones de calidad.
Es un canal suplementario y volátil, no autónomo. Desglosó el algoritmo en cinco fases:
- ingestión y cualificación
- clasificación
- elegibilidad y matching
- ensamblaje en el dispositivo del usuario
- entrega y feedback
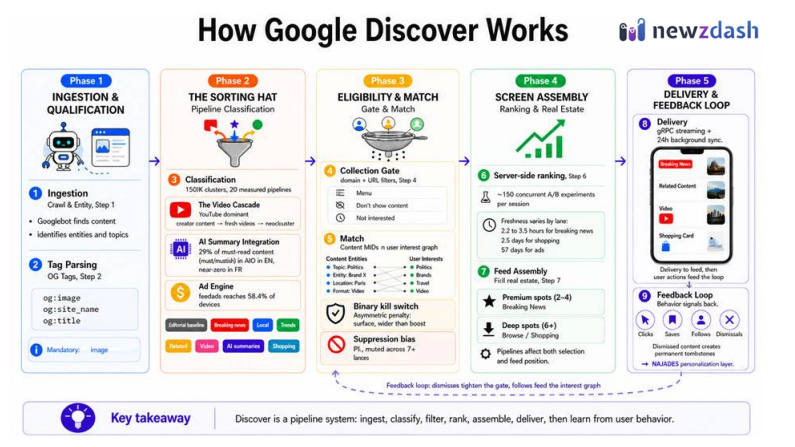
Filtros técnicos críticos:
- imágenes de mínimo 1.200 píxeles
- etiquetas Open Graph cuidadas (OG image, OG site name, OG title)
- presencia explícita de personas, ya que el 28% de los artículos exitosos lleva a una persona nombrada en el titular.
Sobre el Core Update de febrero de 2026 (5-27 feb), un -8% en editores únicos, beneficio claro para el contenido local, listicles muy castigados, y nueva métrica de «autoridad sobre el tema del sitio» que penaliza a los medios generalistas.
Destacó que el último mes YouTube se ha convertido en la fuente número 1 de visibilidad en Discover, X (Twitter) perdió un 88% de visibilidad para el 24 de abril de 2026 y se recuperó casi en tiempo real el 29.
La táctica práctica más rentable que dejó es crear titulares en primera persona, 12-15 palabras, con un OG title diferente al H1 del sitio.
La frase: «Discover ya no es un truco para obtener tráfico. Es una prueba de calidad vestida de feed.«
Sigue al autor:
https://x.com/JShehata
https://www.linkedin.com/in/jshehata
29. Brie Anderson
Ponente: Brie Anderson
Charla: We Had One Job (& It Wasn’t Rankings)
Brie hizo la charla incómoda que la industria necesita escuchar cada cierto tiempo. Llevamos años vendiendo a los clientes la métrica equivocada (visibilidad, tráfico, impresiones) y ahora que las SERPs cambian e introducen IA, los clientes se enfadan incluso cuando las ventas suben.
La culpa no es de la IA, es nuestra, por haber educado mal al mercado durante una década.
Su tesis es directa, esto es, dejad de vender tráfico, empezad a vender resultados de negocio. Y eso requiere dos movimientos.
- Primero, sentarse con el cliente o el stakeholder y descubrir cuáles son sus miedos reales, sus inversiones del año, sus lanzamientos pendientes, sus objetivos… El éxito del SEO se mide en función de cómo apoya esas iniciativas, no en función de cuántas posiciones ganaron este mes en una keyword que a nadie en el comité de dirección le importa.
- Segundo, recordar que el alcance del trabajo SEO es muchísimo más amplio de lo que reportamos, ya que velocidad de página, arquitectura de información, contenido útil, PR digital, UX, todos son palancas que impactan directamente en conversión e ingresos.
Estandarizar UTMs en TODO (perfiles de empresa, sitios de reseñas, guest posts, newsletters, firmas de email), usar informes de atribución multi-touch en GA4 en lugar de seguir mirando el último clic, configurar embudos personalizados para aislar el impacto financiero de elementos concretos (un glosario, una sección de reseñas, un comparador) y mantener un changelog centralizado donde se cruzan actualizaciones algorítmicas, lanzamientos de PR, cambios técnicos y fechas de publicación, para que cuando alguien pregunte «¿esto por qué subió?» tengas respuesta en minutos.

La frase: «Hay una diferencia entre aparecer y darle a alguien la información correcta en el momento adecuado para que tome la decisión correcta, en lugar de simplemente aparecer por aparecer.«
Sigue a la autora:
https://x.com/thatbrieanderson
https://www.linkedin.com/in/brieanderson
30. Zach Chahalis
Ponente: Zach Chahalis, iPullRank
Charla: Why You Need A Relevance Engineer Driving The Car
Zach cerró el día con la analogía de los coches clásicos, que requieren un conductor habilidoso y activo, no piloto automático. La metáfora es para hablar del rol que la industria necesita ya, esto es, el Ingeniero de Relevancia, una figura que combina NLP, ingeniería técnica y estrategia de contenido, y que sustituye al SEO técnico clásico tal y como lo conocíamos.
Su diagnóstico es tajante y es que medir solo rankings y tráfico está muerto. La integración de AI Overviews ya está dañando el tráfico de plataformas dominantes como Wikipedia, así que las nuevas métricas son cuota de voz, tasa de citación, sentimiento de la mención y eventos comerciales reales.
Y para diagnosticar qué está pasando dentro de cada página, iPullRank usa cinco palancas de NLP:
- similitud de coseno de palabras clave (mide coherencia tópica y penaliza la deriva semántica)
- riqueza estratégica de entidades (entidades útiles vs relleno)
- eficiencia explicativa (densidad de hechos vs narrativa vacía)
- afirmaciones verificables (¿pueden corroborarse en otras fuentes de confianza?)
- ganancia de información (¿aporta algo nuevo o repite lo que ya hay?).
El caso real demoledor que enseñó es el de una empresa SaaS que rellenó su blog de «AI slop» fuera de su tema central, esto es, contenido autogenerado sin criterio para inflar volumen. El resultado fue una caída del 90% en posiciones desde enero de 2025 y desaparición casi total de los resultados de IA. En la misma comparativa, sitios de finanzas y tutoriales con alta densidad de información y enfoque temático estricto aguantaron sin despeinarse. El AI slop no es un riesgo teórico, es una sentencia.
Y un detalle técnico que casi nadie monitoriza pero que importa muchísimo: los errores HTTP 499 (timeouts del servidor cuando un agente cancela la petición) correlacionan directamente con la pérdida inmediata de citas en plataformas de IA y solo se recuperan al arreglar el rendimiento técnico.

Si tu servidor es lento, la IA ya ni espera.
La frase: «Tu estrategia es tan buena como el ingeniero de relevancia que conduce el coche. Y a diferencia del piloto automático de Tesla, no puedes simplemente encenderlo, configurarlo y olvidarte.»
Sigue al autor:
https://www.linkedin.com/in/zachchahalis
¿Cuánto ha llevado este post?
El evento ha tenido lugar de 9 de la mañana a 17:00 de la tarde.
He usado como backup Plaud Pro para tomar notas y poder obtener trascripciones, traducciones y resúmenes de las charlas.
Después armar el artículo, con una base de Claude Projects, elegir y recortar las capturas realizadas durante la jornada.
Sin contar la asistencia al evento presencial, el post ha llevado alrededor de 3 horas.
Soy MJ Cachón
Consultora SEO desde 2008, directora de la agencia SEO Laika. Volcada en unir el análisis de datos y el SEO estratégico, con business intelligence usando R, Screaming Frog, SISTRIX, Sitebulb y otras fuentes de datos. Mi filosofía: aprender y compartir.