

En este artículo de Kevin Indig sobre Content Tuning con la API de Google Search Console y el conector de Google Sheets, pues me he puesto como reto tratar de replicarlo en R. (Otra alternativa es esta presentación de Aleyda).
Todo hay que decir que en esto no he estado sola, porque en los últimos tiempos me junto mucho con Kiko Luque para comentar ideas, automatismos y otros scripts R aplicados a SEO que se nos ocurren, nos ayudamos y no podría escribir este post sin mencionarle y darle las gracias por tantos ratos de charla :)
Hecha la introducción, ¿qué es lo que hace este script R?
¡Te lo cuento!
Paso a paso del script
1. Conexión a la API de Google Search Console
Este paso va a pedirte autorización a tu cuenta de gmail donde tengas la cuenta de GSC y te va a listar los sitios a los que tienes acceso. Luego podrás introducir la url en la consola de RStudio y ejecutar el resto del código que extraerá datos web de Page y Query, del ultimo mes (empezando 2 días hacia atrás contando desde hoy)
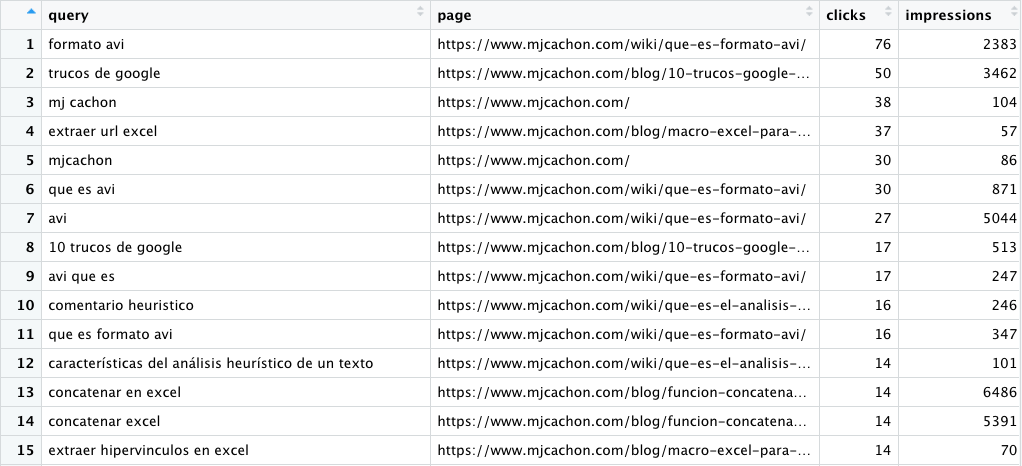
2. Crear un data frame con los datos extraídos de Google Search Console y trabajarlos un poco más
En este caso yo he hecho 2 cosas principalmente:
- Redondear los datos de CTR y Posición, para que coja 2 y 1 decimal(es) respectivamente, luego se verá mejor en el excel final :)
- Crear una columna con el path, basándome en las «/» y las que se quedan vacías, renombrarlas como «Home». Este punto puede ser personalizable en función del proyecto y de su estructura de urls.
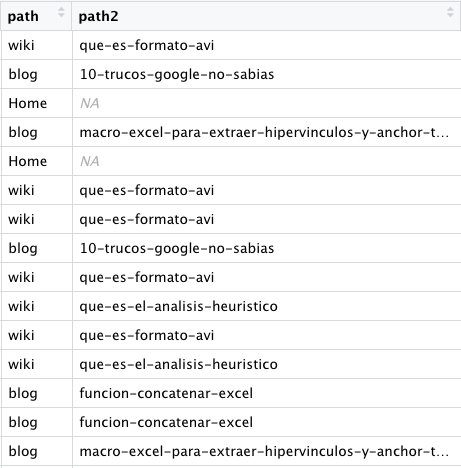
A pensar de haber añadido también path2, siguiendo con el corte de datos con «/», en el caso de mi abandonada web, este elemento sería más bien el slug.
3. Filtrar nuestro data frame con filtros para identificar las optimizaciones con impresiones, clics, posición
A partir del data frame original trabajado en el punto anterior, ahora creamos otro data frame con la información que realmente nos interesa, que la obtendremos filtrando por distintos criterios, tal y como comentaba Kevin en su post:
- Impresiones mayores a 50
- Posición entre 5 y 20 o entre 11 y 20. Aunque es a medida de lo que quiera cada uno.
- Clicks inferiores a 50, 30, 10, lo que encaje mejor con las estadísticas del proyecto elegido.
- Además, se cambia el orden y en vez de mantener el orden descendente por clics, se hace por url, para agrupar keywords con urls fácilmente
Con este paso, la salida será ya vuestra lista de palabras a trabajar en los contenidos, para mejorar el ctr a través de los clics
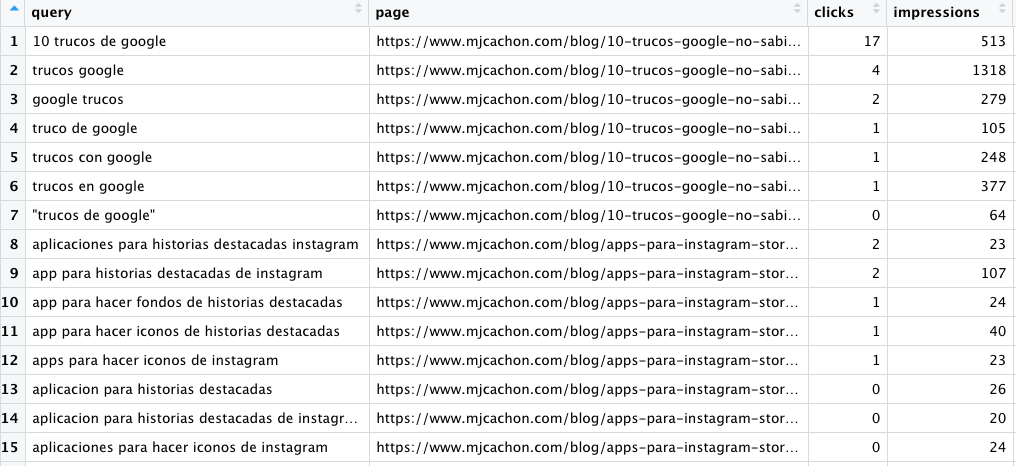
Nota importante: cuando utilizas la API de Google Search Console y llamas a Consultas y Páginas, a la vez, la información que te va a devolver la API está filtrada, del mismo modo que si solicitas consultas brand por un lado y consultas no-brand por otro, cuando sumes los datos, no van a coincidir con los totales que te da la interfaz….
4. Un pequeño resumen de palabras optimizables por cada url y de palabras únicas
En este punto a mi me gusta resumir los datos para ver:
- Cuántas keywords únicas hay para trabajar.
- En qué urls o en qué paths se concentran el mayor número de keywords, es decir, dónde hay que trabajar más.
Esto ya nos da una buena pista de por dónde van los tiros de la optimziación, en lo que respecta a datos del mes anterior.
5. Formato con escalas de color para encontrar antes las oportunidades
Y aquí ya viene uno de los puntos chulos del script, ya que podemos utilizar una librería para usar formatos condicionales.
Para replicar lo que ha hecho Kevin, tan solo se ha usado una escala de colores que van de rojo a verde, en las columnas de clicks, impresiones, ctr y posición, con la librería formattable y usando colores más bien pastel.
La clave aquí es asignar a una variable este formato creado, porque luego nos permitirá descargarlo a un excel, manteniendo el formato.
A pesar de no haberlo avanzado más a nivel estético, la librería permite muchísimas opciones que no tienen nada que envidiar ni a Excel ni a Google Sheets, en lo que a formateado de tablas se refiere, por lo que tiene mucha mejora para un acabado mucho más visual. En mi caso he creado una tabla con los datos originales de GSC y basados en la url, y una segunda tabla que en vez de usar url, se basa en la agrupación por path.
6. Exportar los datos y formatos a un excel
El último paso extrae estas tablas al completo con el formato anterior, por lo que si en el paso de anterior creas varias tablas con variantes de datos, aquí podrás exportarlas en el mismo fichero, una en cada pestaña. En minutos, el trabajo tedioso hecho, ya solo te queda analizar y pensar acciones de mejora :)
Script completo
install.packages("searchConsoleR")
install.packages("tidyverse")
library(searchConsoleR)
library(tidyverse)
# cambiar por tu carpeta de descarga preferida
setwd("~/Desktop/pruebasR")
# 1- CONEXIÓN A GSC
#Solicita autorización a la cuenta
scr_auth()
#Saca listado de propiedades de cuenta para ver si las ha cogido bien
sc_websites <- list_websites()
sc_websites
my.url <- readline(prompt="Introduce URL exacta de tu sitio: ")
fecha_inicio <- as.Date(Sys.Date() - 30)
fecha_final <- as.Date(Sys.Date() - 2)
tipo <- c("web")
datos_fechas <-as_tibble(
search_analytics(siteURL = my.url,
startDate = fecha_inicio,
endDate = fecha_final,
c("query","page"), #aqu? podr?amos poner por ej. ("page","query")
searchType = tipo,
))
# 2- TRABAJAR LOS DATOS DE GSC EN UN DATAFRAME
# redondear ctr y posición
datos_fechas$ctr <- round(datos_fechas$ctr,digits=2)
datos_fechas$position <- round(datos_fechas$position,digits=1)
# crear campo path y path2
split <- strsplit(as.character(datos_fechas$page), "/", fixed = TRUE)
datos_fechas$path <- sapply(split, "[", 4)
datos_fechas$path[is.na(datos_fechas$path)]<- "Home"
datos_fechas$path2 <- sapply(split, "[", 5)
# 3- CREAR DATAFRAME CON LOS FILTROS DESEADOS PARA OBTENER LAS KWS OPTIMIZABLES
# crear dataframe con las Keywords a optimizar, usando filtros
optimizar_kw <- datos_fechas %>%
filter(impressions >= 20 & position > 5 & position < 20 & clicks <= 20 ) %>%
arrange(page)
# 4- CREAR DATAFRAME RESUMEN CON Nº KEYWORDS A OPTIMIZAR POR URL
# contar nª de keywords optimizables por cada url, como resumen
data_count <- optimizar_kw %>%
group_by(path) %>%
dplyr::summarise(count = n_distinct(query)) %>%
arrange(desc(count))
# contar nª de keywords repetidas, como resumen
kw_count <- optimizar_kw %>%
group_by(query) %>%
dplyr::summarise(count = n_distinct(query)) %>%
arrange(desc(count))
# 5- FORMATO CONDICIONAL PARA LAS COLUMNAS
# Usar formattable en lugar de condformat
library(formattable)
# Colores pastel suaves
color_verde_pastel <- "#b8e6b8" # Verde pastel
color_rojo_pastel <- "#ffcdd2" # Rojo pastel
# para sacar la tabla entera con escala de color
tabla_formateada1 <- formattable(optimizar_kw[,c(1:6)],
align = c("l", "l", "r", "r", "r", "r"), # izq para texto, der para números
list(
clicks = color_tile(color_rojo_pastel, color_verde_pastel),
impressions = color_tile(color_rojo_pastel, color_verde_pastel),
ctr = color_tile(color_rojo_pastel, color_verde_pastel),
position = color_tile(color_verde_pastel, color_rojo_pastel) # Inverso porque menor es mejor
)
)
# para sacar query, path y datos numéricos con escala de color
tabla_formateada2 <- formattable(optimizar_kw[,c(1,7,3,4,5,6)],
align = c("l", "l", "r", "r", "r", "r"), # izq para texto, der para números
list(
clicks = color_tile(color_rojo_pastel, color_verde_pastel),
impressions = color_tile(color_rojo_pastel, color_verde_pastel),
ctr = color_tile(color_rojo_pastel, color_verde_pastel),
position = color_tile(color_verde_pastel, color_rojo_pastel) # Inverso porque menor es mejor
)
)
# 6- EXPORTAR EN UN EXCEL, POR PESTAÑAS
# Guardar las tablas formattable como HTML primero
library(htmltools)
library(htmlwidgets)
# Función para guardar formattable
save_formattable <- function(f, file) {
w <- as.htmlwidget(f)
saveWidget(w, file = file, selfcontained = TRUE)
}
# Guardar como HTML
save_formattable(tabla_formateada1, "tabla1_temp.html")
save_formattable(tabla_formateada2, "tabla2_temp.html")
# Usar openxlsx para crear Excel con formato
library(openxlsx)
wb <- createWorkbook()
addWorksheet(wb, "kw-url")
addWorksheet(wb, "kw-path")
writeData(wb, sheet = 1, optimizar_kw[,c(1:6)])
writeData(wb, sheet = 2, optimizar_kw[,c(1,7,3,4,5,6)])
saveWorkbook(wb, "excel_gsc.xlsx", overwrite = TRUE)Conclusiones y siguientes pasos
El lenguaje R es muy potente para extracción, procesamiento y visualización de datos, así cómo para iniciarse en ciencia de datos y aprendizaje automático. Scripts como el que hoy comparto, pueden ser muy útiles para evitar hacer tareas mecánicas o manuales, ya que desde RStudio se puede ejecutar de golpe el script entero y los ficheros de salida aparecerían en la carpeta que hubieras designado en tu sesión de RStudio. ¿Fácil, verdad? La evolución de scripts como estos puede ir orientada a trabajar la parte semántica, a través de corpus y matrices de documentos para hacer detección de entidades, nubes de topics, y todo lo relacionado con text mining, con lo que ello conlleva en el mundo SEO.
Librerías utilizadas
- Desde el punto 1 al 4:
- Puntos 5 y 6:
Soy MJ Cachón
Consultora SEO desde 2008, directora de la agencia SEO Laika. Volcada en unir el análisis de datos y el SEO estratégico, con business intelligence usando R, Screaming Frog, SISTRIX, Sitebulb y otras fuentes de datos. Mi filosofía: aprender y compartir.
Explorar por temas
tal vez sea
de tu interés
-
Cómo fusionar ficheros excel con r
En este post quiero compartir un pequeño y simple script que ayuda a fusionar todos los excel descargados, eliminar filas de keywords sin volumen, ordenar los datos de mayor a menor volumen y poner un 0 en aquellos campos de volumen estacional que vengan vacíos. ¡Vamos a explicarlo paso a paso!
Leer artículo -

Correlación de datos en nuestros análisis SEO: qué tener en cuenta
Llevo muchos años haciéndolo mal, lo reconozco, ha sido por puro desconocimiento: no sabía lo que tenía que saber. ¿Qué paradoja, verdad?
Leer artículo -
Caché de Google: ¿Cómo usarlo?
La caché de Google es útil para SEO porque nos permite ver «con ojos de Google» qué elementos han sido rastreados y cuál es la última versión que Google guardó de una web. Tal y como dice Google: «Los enlaces en caché muestran cómo era la página web la última vez que Google la visitó.» … Caché de Google: ¿Cómo usarlo?
Leer artículo
3 comentarios
Excelente artículo y te felicito por los primeros pasos en RStudio ya que es muy potente y poco a poco se le esta dando mayor difusión.
todo lo que sea automatización me encanta ! no había oido de r , ya no es un día perdido ahora aparte informamrme en tu blog , revisare que tiene de bueno kevin en su blog.
saludos desde Chile
Excelente Post, gracias por tu aportación de gran valora, intentaremos aplicarlo a nuestra inmobiliaria! Saludos ;)