

Hace tiempo leyendo las guidelines de Google me di cuenta de un pequeño detalle que quizás haya podido pasar desapercibido para mucha gente.
Se trata de cómo deben crearse las instrucciones Disallow o Allow en el fichero robots.txt. A continuación el fragmento de las guidelines al que me refiero:
Puedes leer esa parte de la documentación en este enlace.
Me puse a pensar que ya había visto muchos robots.txt en los que las instrucciones no empezaban por «/», en contra de lo que dice Google y la verdad que aunque me pregunté por qué, desconozco la razón.
¿Acaso es que esa pauta, da igual? ¿La respeta Google o no la respeta? ¿En verdad se puede interpretar de otra forma la explicación que da Google en sus guidelines?
EL EXPERIMENTO EN Y CON MI WEB
A finales de junio modifiqué mi archivo robots.txt para eliminar la barra de inicio de cada instrucción: el 28 de junio a las 22:17. El aspecto del fichero quedó así:
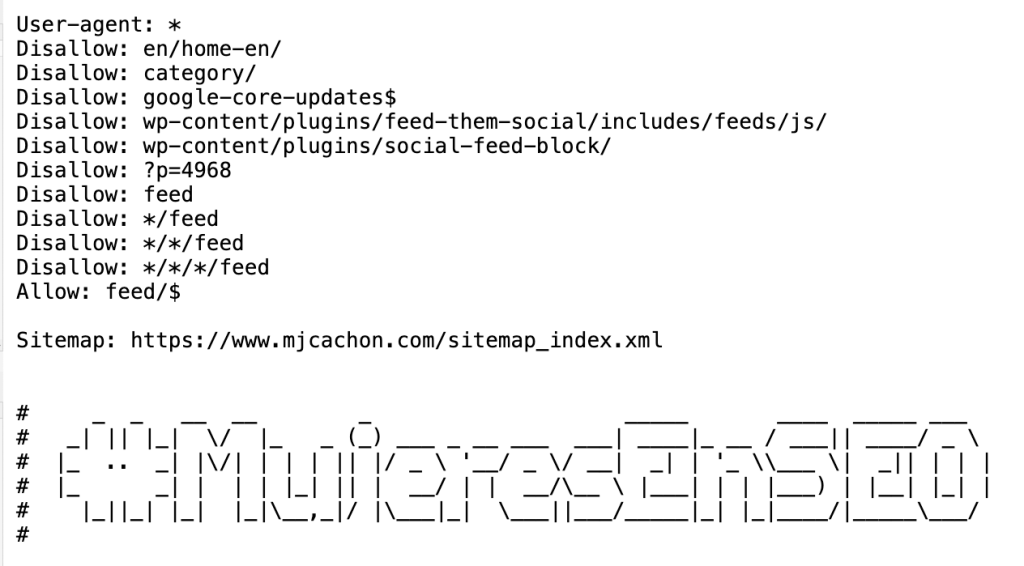
Como se puede ver, las instrucciones quedaron huérfanas de barra inicial (/) tal y como se entiende de las guidelines.
Lo que yo quería comprobar era:
- Si esos Disallow iban a ser respetados o no
Y lo iba a comprobar así:
- Revisando los accesos al servidor (logs) por parte de Googlebot
He descartado usar las estadísticas de rastreo de Google Search Console porque solo nos ofrece una muestra.
Así que si después de la fecha de cambiar el fichero robots.txt alguno de los patrones de urls incluidos en el fichero recibían accesos por parte de Googlebot, eso significaría que la regla no se respeta sin la barra.
Ahora solo faltaba esperar a ver qué pasaba, aunque con un hándicap claro: el rastreo de mi web es muy bajo, en su día eliminé muchos contenidos y, habitualmente, no genero muchas piezas de contenido.
LOS RESULTADOS
Tras más de un mes, escribo este post a 31 de julio después de revisar los logs que me facilita Raiola Networks.
Adjunto algunos de los patrones bloqueados y su impacto en los logs, considerando que hay ciertas páginas que tienen un presupuesto de rastreo ínfimo, pues es algo que ha podido afectar al experimento o que aún no tenga datos
Patrones que han recibido hits por parte de Googlebot:
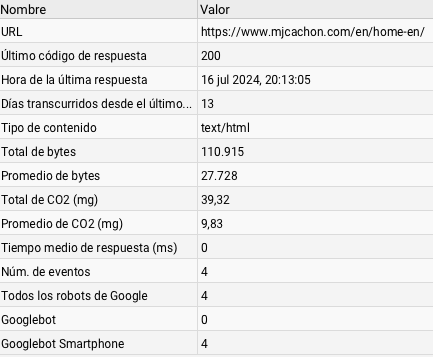
- en/home-en/ ha recibido varios accesos, algunos antes del cambio de robots.txt y otros después

Y si nos fijamos en la última petición, este es el detalle:
- Recursos css o js, que son más accedidos o con más frecuencia, si han sido accedidos con normalidad a pesar de la instrucción Disallow sin barra

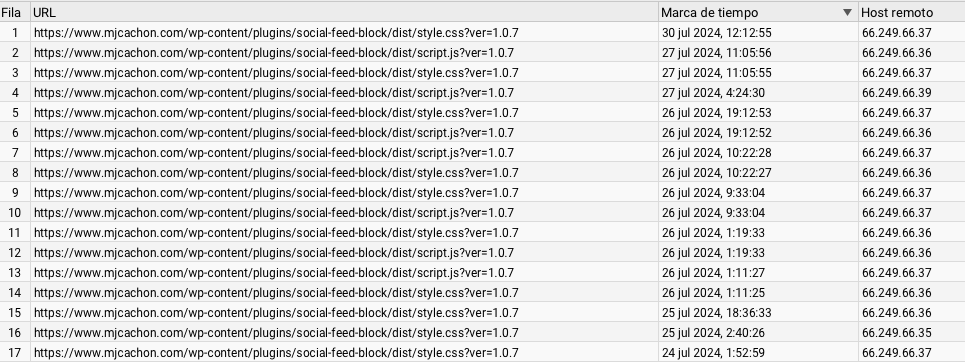
- Páginas de patrón «category» que en muchos casos son páginas antiguas, pero han recibido accesos igualmente, en este caso, es la url de la primera fila la que ha sido rastreada a pesar del robots.txt.

COMPROBACIÓN CON EL INSPECTOR DE URLS DE GOOGLE SEARCH CONSOLE
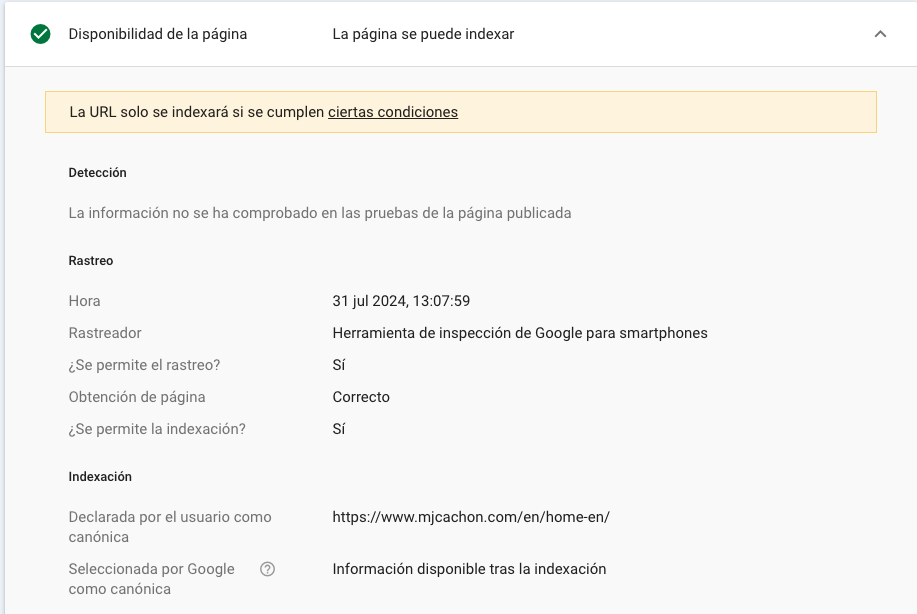
A pesar de la instrucción en el robots.txt cuya intención es bloquear, a pesar de iniciar la línea sin la barra, el inspector de urls de Google Search Console entiende que esas líneas no suponen un bloqueo o no cumplen con la nomenclatura requerida.
Se permite el rastreo si la línea del Disallow NO empieza por barra
SEGUNDO EXPERIMENTO PARA VALIDAR
A pesar de los resultados, voy a iniciar hoy mismo un segundo test para validar los resultados del primero, que al tener un crawl budget tan bajito, vamos a probarlo en un sitio con más movimiento para confirmar si el comportamiento es el mismo.
ACTUALIZACIÓN:
- el segundo test confirma que las instrucciones SIN barra no son respetadas por Googlebot, por lo que rastrea los patrones indicados
- he aprovechado para poner Disallow: url-inventada/ para comprobar si puede usar esos patrones para descubrir nuevas urls, pero no he visto ni rastro en los Logs de ningún accceso a la url inventada
¿HAY QUE HABLAR MÁS DE ESTO PARA EVITAR PROBLEMAS TÉCNICOS?
Definitivamente SI.
A raíz de esto, he analizado alrededor de 1000 webs de diversos sectores y compruebo que hay muchas webs que usan las instrucciones sin la barra inicial, por lo que, presumiblemente, puede que esas instrucciones no estén bloqueando lo que realmente quieren con el consiguiente desperdicio de rastreo.
Para no evidenciar casos concretos, me limito a añadir las tablas de sectores.
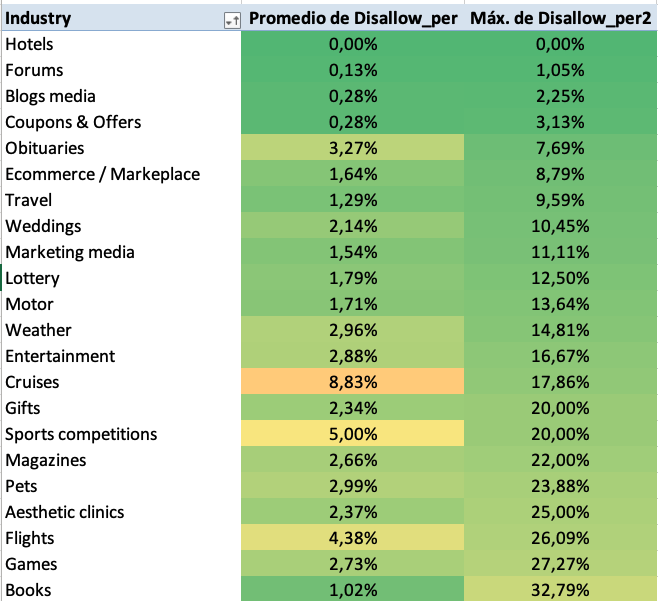
- Sectores que lo hacen según indican las Guidelines de Google, añado el promedio por sector y el valor porcentual máximo de Disallows sin barra, para ilustrar el buen uso.
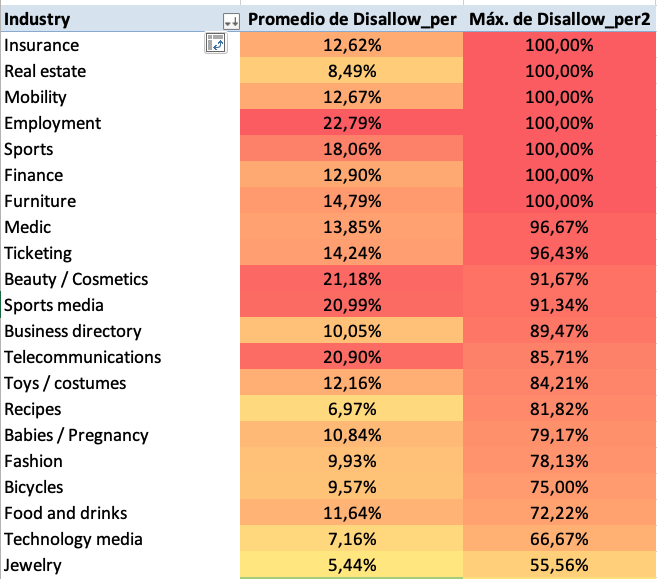
- Sectores que no lo hacen según indican las Guidelines de Google, añado el promedio por sector y el valor porcentual máximo de Disallows sin barra, para ilustrar el uso actual.
Conclusiones y siguientes pasos
La conclusión es clara: debemos conocer al detalle las guidelines de Google y entender las implicaciones técnicas de no aplicar las instrucciones o directivas en el formato y requisitos indicados.
En las siguientes semanas actualizaré el artículo con los resultados del segundo test que puedan validar la hipótesis inicial.
Si tienes experiencias al respecto, deja un comentario y aporta a la conversación :)
Soy MJ Cachón
Consultora SEO desde 2008, directora de la agencia SEO Laika. Volcada en unir el análisis de datos y el SEO estratégico, con business intelligence usando R, Screaming Frog, SISTRIX, Sitebulb y otras fuentes de datos. Mi filosofía: aprender y compartir.