
Las apis de las herramientas son una puerta de entrada ideal para aquellos SEOs que buscan acceder a datos de forma algo más «masiva» y automatizada, para construir sus propios modelos de extracción, limpieza, fusión y procesado de datos.
Hoy vuelvo con R a compartir algunas líneas que pueden ser de mucha utilidad para quien quiera exprimir los datos de SISTRIX desde R y explicaré también ejemplos de casos de uso donde aplicar los scripts.
[DISCLAIMER: estoy segura que todo lo que yo cuento aquí se puede hacer de millones de formas más ágiles y eficientes, usando menos código o menos librerías, ¡estoy empezando! ]
Primeros pasos con la api de SISTRIX
Para acceder a la api solo necesitamos una api_key, que se crea desde tu cuenta de pago de SISTRIX y tener clara la documentación de la api de los datos que están disponibles para acceder. Por resumir, hay una url por cada método, es decir, por cada tipo de datos que vamos a requerir, pero para simplificar, se explica en este post cómo extraer el índice de visibilidad. La url de una petición será como esta:
https://api.sistrix.com/domain.sichtbarkeitsindex?api_key=[API_KEY]&domain=sistrix.com
- https://api.sistrix.com/domain.sichtbarkeitsindex? –> esto es la url base
- api_key=[API_KEY] –> esto es el parámetro api_key, cuyo valor debe coincidir con tu clave
- domain=sistrix.com –> esto es el parámetro domain, cuyo valor será el dominio del que quieres extraer la visibilidad. Podrías usar en su lugar host para subdominios, path para directorios y url para urls.
En esta petición, al no indicar nada más, nos daría la visibilidad de Alemania del último lunes disponible. Para eso sirve conocer los parámetros opcionales:
- history=yes&num=12, si quisieras extraer la visibilidad de las 12 últimas semanas
- date, para obtener la visibilidad de una fecha concreta, el formato es AAAA-MM-DD
- mobile=yes, para indicar que queremos datos de mobile, en vez de desktop
- country=es, si queremos el dato del mercado español (otros mercados de, at, ch, it, es, fr, pl, nl, uk, us, se, br, tr, be, ie, pt, dk, no, fi, gr, hu, sk, cz, au, jp, ca)
- extended=yes, si queremos obtener datos de la base de datos completa, no solo de la base de datos del índice de visibilidad.
Cada método en la API, puede tener unos parámetros opcionales diferentes, tan solo hay que leer la documentación y quedarse con la copla :)
Acceso a la api: petición individual
Si queremos hacer una petición a un dominio individual, podemos hacerlo así
Paso 1: instalar y llamar a las librerías necesarias
install.packages("httr")
install.packages("jsonlite")
install.packages("lubridate")
install.packages("ggplot2")
install.packages("writexl")
library("writexl")
library(httr)
library(jsonlite)
library(lubridate)
library(ggplot2)
Paso 2: definir las variables y parámetros que hacen falta para la petición
api_key <- "Tu_Clave_Serán_Letras_Y_Numeros" base_url = "https://api.sistrix.com/domain.sichtbarkeitsindex?" country <- "es" mobile <- "yes" domain <- "holaluz.com"
Paso 3: hacer la petición
Podemos hacerlo en 2 pasos para entenderlo mejor: primero construimos lo que sería la url a la que llamamos (full_url) y luego la llamamos (res)
full_url = paste0(base_url, "api_key=",api_key, "&", "domain=",domain, "&", "country=", country, "&", "mobile=",mobile, "&format=json") res = GET(full_url)
Si ejecutáis la variable full_url veréis que se compone una url como esta:
https://api.sistrix.com/domain.sichtbarkeitsindex?api_key=Tu_Clave_Serán_Letras_Y_Numeros&domain=holaluz.com&country=es&mobile=yes&format=json
Si la abrís en el navegador os mostrará, en formato json, los datos extraídos de la api:
[{"domain":"holaluz.com","date":"2021-04-12T00:00:00+02:00","value":1.215}]}],"credits":[{"used":1}]}
Paso 4: convertir el json en datos que podamos manejar
datos = fromJSON(rawToChar(res$content)) datos2 <- datos$answer[[1]][[1]] datos2$date <- as.Date(datos2$date)
Con estas 3 lineas se parsea el json y al ser una lista de datos, pues la pasamos a un dataframe, más manejable para lo que queramos hacer con ello.
El formato de fecha se adapta como paso final
Paso 5: descargar fichero e imágenes (optativo)
write_xlsx(df,"fichero.xlsx")
ggsave("como-quieres-que-se-llame-la-imagen.png", plot = nombre-del-grafico)
Acceso a la api: loop para que recorra un listado de sitios
Si lo que nos interesa es acceder a datos en bulk de una lista de dominios, en vez de hacerlo uno a uno, podemos hacer algunas modificaciones
Por ejemplo, la variable domain, la puedo construir como un vector de elementos
domain <- c("holaluz.com","comparadorluz.com","tarifaluzhora.es","endesa.com","iberdrola.es")
Y ahora tenemos que hacer que el paso 3 se haga sobre los 5 dominios del vector, por lo que usaremos un loop. Como aspectos interesantes, se crea una lista vacía llamada datos y se crea una variable de delay, para que haya tiempo entre petición y petición
datos <- list()
delay_seconds<-2
for (i in (domain)) {
raw_get <- GET(paste0(base_url, "api_key=",api_key, "&", "domain=",i, "&",
"country=", country, "&", "mobile=",mobile, "&format=json"))
date_time<-Sys.time()
while((as.numeric(Sys.time()) - as.numeric(date_time))<delay_seconds){}
real_get <- fromJSON(rawToChar(raw_get$content))
datos[[i]] <- real_get$answer[[1]][[1]]
}
df <- as.data.frame(do.call(rbind, datos))
df$date <- as.Date(df$date)
Las 2 líneas finales se encargan de su posterior transformación a un fichero más manejable
Casos de uso SEO: ¿cómo usamos esto?
Visibilidad histórica de mi web y mis competidores
Hace unos meses, desde SISTRIX se hicieron una serie de aproximaciones con la API a través de importXML y posteriormente Carlos Ortega replico alguna en su blog usando Google Sheets
Este mismo análisis es posible con lo que comento en este post (usando la variable history) y un punto extra que sería la visualización:
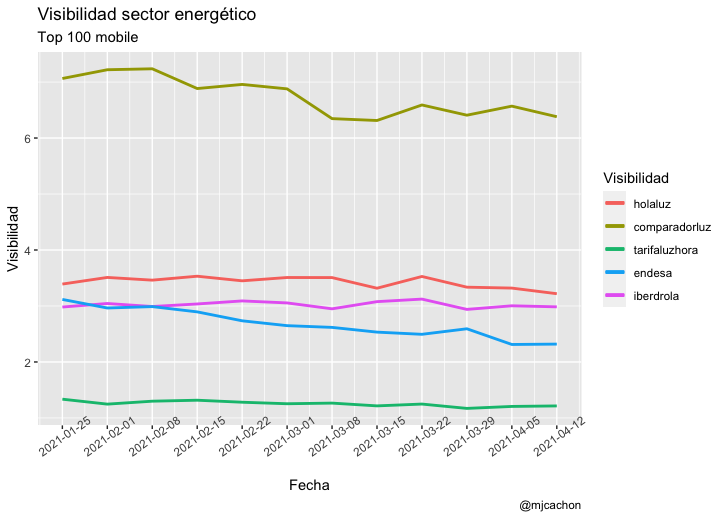
Lo potente de esto es que el script puede ir contra un fichero de dominios y extraer y pintar todo él solito
Fusionar datos de SISTRIX a los datos de Screaming Frog
Una conexión que todavía no existe en Screaming Frog es la posibilidad de conectar la API de SISTRIX, cosa que por el momento, es posible replicar con R, sin mucho problema.
Por ejemplo, si rastreamos una página web en Screaming Frog, usando datos extra de Google Anaytics y de Page Speed, podríamos hacer uso del loop comentado para incorporar datos de SISTRIX
Ahora nuestra variable domain será sustituida por url y será la columna «Address» del fichero Internal_all.xlsx que descarguemos de Screaming Frog y subamos a R, y a partir de ahí:
- Un loop para extraer el índice de visibilidad, usando el parámetro url
- Un loop para extraer keywords posicionadas en el top 100 de cada url
- Un loop para extraer keywords posicionadas en el top 10 de cada url
- Se podría añadir también el número de backlinks, aunque en Screaming Frog si se puede conectar Ahrefs.

Análisis sectoriales en Core Updates o en cualquier momento
En el último Core Update de Diciembre, me lié la manta a la cabeza y terminé sacando datos durante 4 semanas, de un set de dominios repartidos por sectores, una lista que acabó superando los 1000 dominios (podéis ver el post y el documento completo aquí). Hacer estos análisis usando importXML de Spreadsheets, ha sido un quebradero de cabeza absoluto, algo que ahora puedo escalar un poquito y al menos agilizar una parte del análisis considerablemente.
Para esto se usa el procedimiento comentado del loop para un listado de dominios y podemos llegar a procesarlo relativamente rápido, siempre respetando los límites de la API:
La API está limitada a 300 visitas por minuto por cuenta de en la herramienta. Debe haber al menos 300 ms entre dos consultas. Si estos límites se exceden permanentemente, la API responde con el código de estado 429 (Too many requests), pero no calcula los créditos para esta consulta.
El ejemplo aplicado sería lanzar 2 loop para 2 fechas diferentes (hoy vs core update diciembre) y luego pintarlo de la forma que más nos apetezca :)
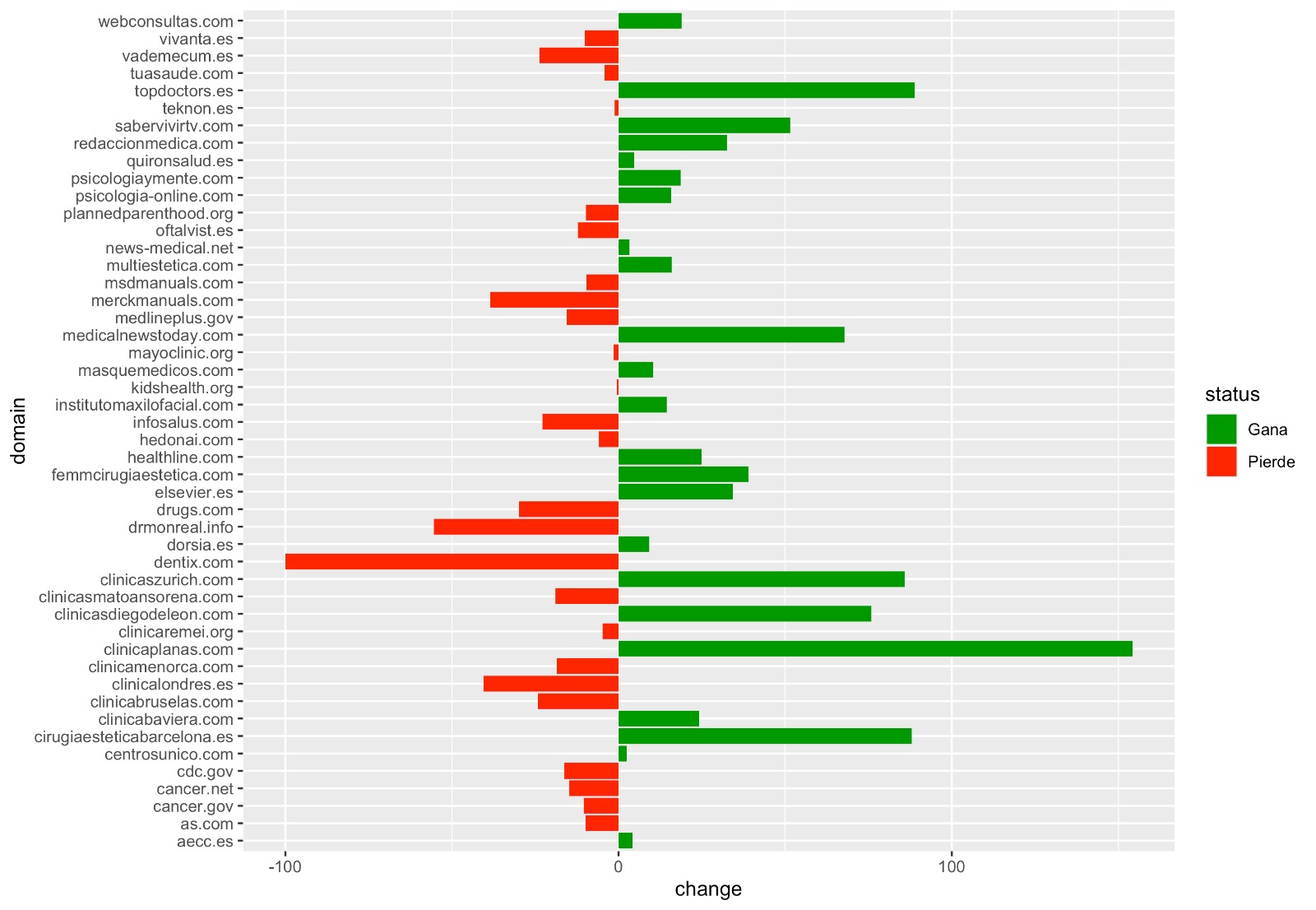
Y por hoy, esto es todo, espero que os haya servido de inspiración o para picaros con R y SEO un poquito más
¿Se os ocurren otros usos que puedan ser interesantes?
Soy MJ Cachón
Consultora SEO desde 2008, directora de la agencia SEO Laika. Volcada en unir el análisis de datos y el SEO estratégico, con business intelligence usando R, Screaming Frog, SISTRIX, Sitebulb y otras fuentes de datos. Mi filosofía: aprender y compartir.
Explorar por temas
tal vez sea
de tu interés
-

Cómo extraer la visibilidad de SISTRIX usando Screaming Frog
Este es un post rápido para explicar cómo extraer la visibilidad de SISTRIX utilizando Screaming Frog, nuestra rana amiga. Para poder seguir este post vas a necesitar: ¡Vamos a ver cómo hacerlo!
Leer artículo -
Disavow tool de Google: novedades para desautorizar enlaces
Nueva Herramienta: Disavow Links Esta semana hemos sido testigos del lanzamiento de una nueva herramienta por parte del equipo de calidad de Google, liderado por tito Matt Cutts: la herramienta se ha llamado Disavow Links Tools o herramienta de desautorización de enlaces. A priori la creación de herramienta Disavow Tool, viene a cumplir una función … Disavow tool de Google: novedades para desautorizar enlaces
Leer artículo -

Análisis de competencia SEO usando estadística: mi TFM de Estadística Aplicada con R
Acabo de terminar mi Trabajo de Fin de Máster del Máster de Estadística con R de Máxima Formación junto a la Universidad Nebrija (gracias Rosana Ferrero por el apoyo y seguimiento durante el máster) y quería compartir un resumen de lo que he hecho, porque creo que puede ser útil para quienes trabajan en SEO … Análisis de competencia SEO usando estadística: mi TFM de Estadística Aplicada con R
Leer artículo