
Hace unos meses escribí un artículo en el blog de SISTRIX en el que usaba fórmulas de excel y google sheets para trabajar el procesamiento y visualización de datos de visibilidad obtenidos con la herramienta (podéis leer el artículo aquí).
[DISCLAIMER: estoy segura que todo lo que yo cuento aquí se puede hacer de millones de formas más ágiles y eficientes, usando menos código o menos librerías, ¡estoy empezando! ]
Antes de nada: cómo extraer los datos para que funcione el script
Para este post, voy a analizar la visibilidad de sistrix.es y para ello, tan solo hay que:
- Abrir el módulo SEO y añadir el dominio
- Ir a la sección de palabras clave
- Filtrar por palabras con volumen mayor a 0
- Ir a opciones y «Elegir Columnas», marcar los campos que se ven en la imagen y descargar.
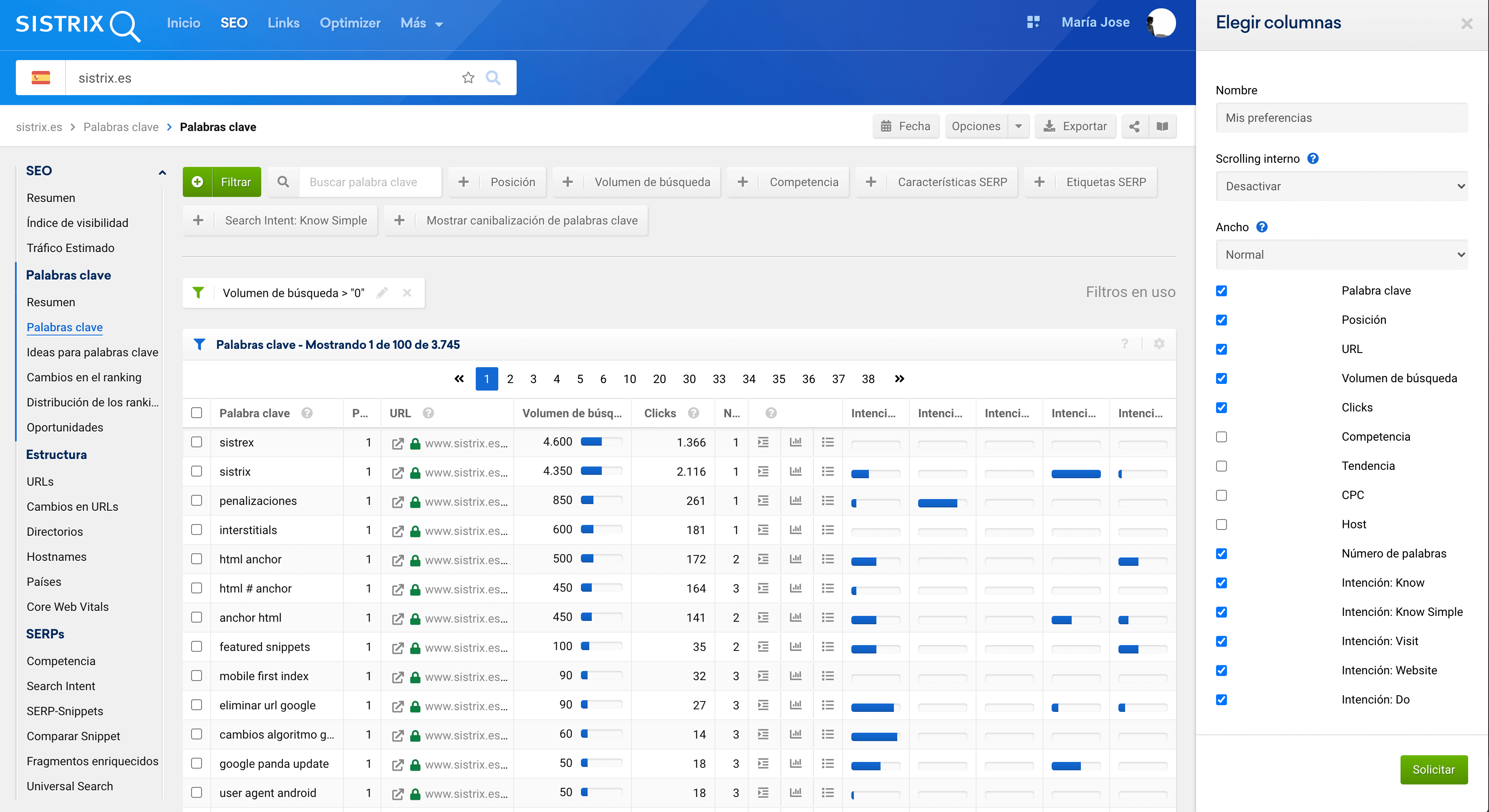
En la imagen ya podéis ver una funcionalidad nueva que puede dar mucho juego: Clicks. Con esto podéis calcular el CTR específico de vuestras keywords usando el volumen, y ya comparar con Google Search Console, o mejor, con vuestra competencia ? Pero no estamos aquí para esto.
Yo renombro el excel descargado a data.xlsx, para subirlo a R y que el script haga el resto.
Qué hace el script para analizar la visibilidad desde varios criterios
Subimos el excel a R, renombramos los nombres de las columnas y quitamos los NAs
En este punto, se añaden nombres de columna específicos
colnames(datos) <- c('kw','pos','url','vol','clicks', 'tail','know', 'knowsimple', 'visit', 'website', 'do')
Para ver si hay NAs, se puede ver a simple vista observando los datos, o bien, haciendo
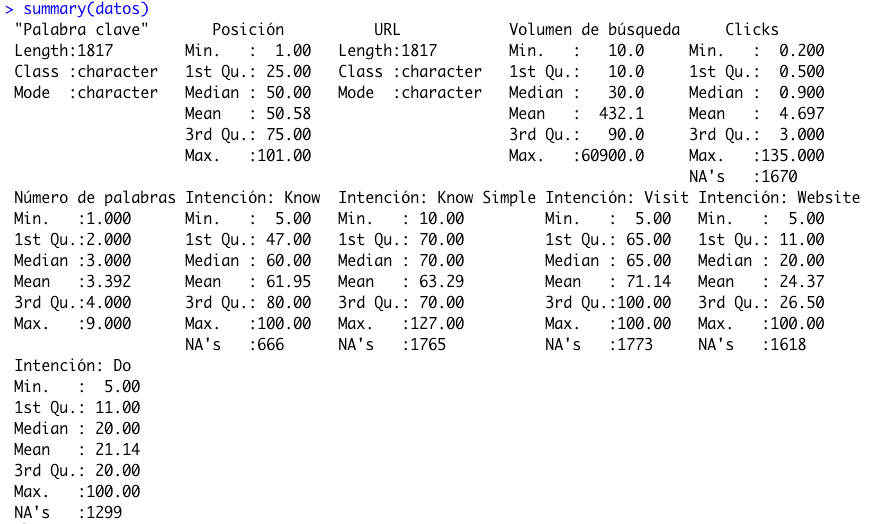
summary(datos)
El output nos dejará ver dónde hay campos vacíos, además de una pequeña estadística descriptiva básica
El total de NAs también se puede obtener como una suma para hacernos a la idea del alcance total
sum(is.na(datos))
Se cambian los NAs que son valores vacíos del excel, por 0 o por lo que nos permita identificar valores vacíos y no se confunda con valores añadidos por nosotros
datos$know[is.na(datos$know)] <- 0
datos$knowsimple[is.na(datos$knowsimple)] <- 0
datos$visit[is.na(datos$visit)] <- 0
datos$website[is.na(datos$website)] <- 0
datos$do[is.na(datos$do)] <- 0
datos$vol[is.na(datos$vol)] <- 1
datos$pos[is.na(datos$pos)] <- 111
datos$clicks[is.na(datos$clicks)] <- 0
En el caso de volumen (vol), no nos hace falta para este caso, porque los datos ya vienen filtrados por valores mayores que cero, pero si no hubiera hecho ese filtro, ya cambiaríamos todos los ceros por 1, en el campo volumen.
Creación de nuevos campos a partir de los datos de origen
- palabra de marca o no
datos$brand <- grepl("^sistr", datos$kw)
datos$brand[datos$brand=="TRUE"] <- "Brand"
datos$brand[datos$brand==FALSE] <- "No brand"
- path de la url y nombrar «Home» a la home.
split <- strsplit(as.character(datos$url), "/", fixed = TRUE) datos$path1 <- sapply(split, "[", 4) datos$path1[is.na(datos$path1)]<- "Home"
- clasificamos el tipo de visibilidad en muy buena, buena, regular o mala, en base a las posiciones, esto cada uno lo puede personalizar como quiera
datos$visibilidad[datos$pos < 6] <- "Muy buena" datos$visibilidad[datos$pos > 5 & datos$pos < 11] <- "Buena" datos$visibilidad[datos$pos > 10 & datos$pos <21] <- "Regular" datos$visibilidad[datos$pos > 20] <- "Mala"
- longitud de la keyword como short, mid o long tail, en base al número de palabras que tenga la keyword, esto cada uno lo puede personalizar como quiera
datos$kw_type[datos$tail == 1] <- «Short»
datos$kw_type[datos$tail > 1 & datos$tail < 4] <- «Mid»
datos$kw_type[datos$tail > 3] <- «Long»
- clasificamos el volumen en alto, medio o bajo, esto cada uno lo puede personalizar como quiera
datos$volumen[datos$vol > 999] <- "Alto" datos$volumen[datos$vol > 100 & datos$vol < 1000] <- "Medio" datos$volumen[datos$vol < 101] <- "Bajo"
- página de google, en base a la posición
datos$pagina_google[datos$pos < 11] <- "001" datos$pagina_google[datos$pos > 10 & datos$pos < 21] <- "002" datos$pagina_google[datos$pos > 20 & datos$pos < 31] <- "003" datos$pagina_google[datos$pos > 30 & datos$pos < 41] <- "004" datos$pagina_google[datos$pos > 40 & datos$pos < 51] <- "005" datos$pagina_google[datos$pos > 50 & datos$pos < 61] <- "006" datos$pagina_google[datos$pos > 60 & datos$pos < 71] <- "007" datos$pagina_google[datos$pos > 70 & datos$pos < 81] <- "008" datos$pagina_google[datos$pos > 80 & datos$pos < 91] <- "009" datos$pagina_google[datos$pos > 90 & datos$pos < 101] <- "010" datos$pagina_google[datos$pos > 100 & datos$pos < 111] <- "100" datos$pagina_google[datos$pos > 110] <- "111"
- intención de búsqueda predominante, basándonos en el dato que proporciona SISTRIX (se establece el más alto como predominante y la ambigua ocurre cuando no hay ninguna intención que supere a las demás)
datos$intent <-ifelse(datos$know > datos$knowsimple & datos$know > datos$visit & datos$know > datos$website & datos$know > datos$do,"Know", ifelse (datos$knowsimple > datos$know & datos$knowsimple > datos$visit & datos$knowsimple > datos$website & datos$knowsimple > datos$do,"Know simple", ifelse(datos$do > datos$knowsimple & datos$do > datos$visit & datos$do > datos$website & datos$do > datos$know,"Do", ifelse (datos$website > datos$knowsimple & datos$website > datos$visit & datos$website > datos$do & datos$website > datos$know,"Website", "Ambigua"))))
- ctr por posición, ya que SISTRIX ahora muestra clics esperados, en la tabla de keywords.
datos$ctr <- (datos$clicks / datos$vol)*100 datos$ctr[is.na(datos$ctr)] <- 0
Opciones de personalización
Nuestro fichero de datos ha pasado de 11 variables en su origen, a tener 20, con las que hemos construido.
A partir de aquí ya necesitamos tirar de librerías y de cara a visualizar gráficos, podemos usar colores personalizados (he usado los típicos colores de excel) y un logo, para añadir si nos apetece personalizarlo más.
install.packages("dplyr")
install.packages("ggplot2")
install.packages("magick")
library(ggplot2)
library(magick)
library(dplyr)
excel <-c("#002060", "#A5A5A5", "#FFC000", "#ED7D31", "#4472C4")
logo <- image_read("sistrix-logo.png")
Agrupar datos y pintarlos: usando solo un criterio
Si estuviéramos en Excel o Sheets, quizás usaríamos métodos como tablas dinámicas, para agrupar la información y luego hacer gráficos con ello.
Aquí podemos usar dplyr para lo mismo, empezamos con cálculos con una sola variable
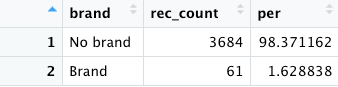
- Distribución de rankings por marca o no marca
brand <- datos %>%
group_by(brand) %>%
dplyr::summarise(rec_count = n()) %>%
dplyr::mutate(per=rec_count/nrow(datos)*100.0) %>%
dplyr::arrange(desc(rec_count))
La visualización básica
gra_brand <- ggplot(brand, aes(x=brand, y=per, fill = rec_count, label = rec_count)) +
geom_line(color="blue")+ xlab("Tipo keyword") + ylab("% Rankings") + labs(title="Visibilidad por nº de rankings brand vs no brand")+
geom_bar(stat = "identity", width = 0.5)+
geom_text(aes(label = round(per, digits = 2)), position=position_dodge(width=0.9), vjust=-0.25)
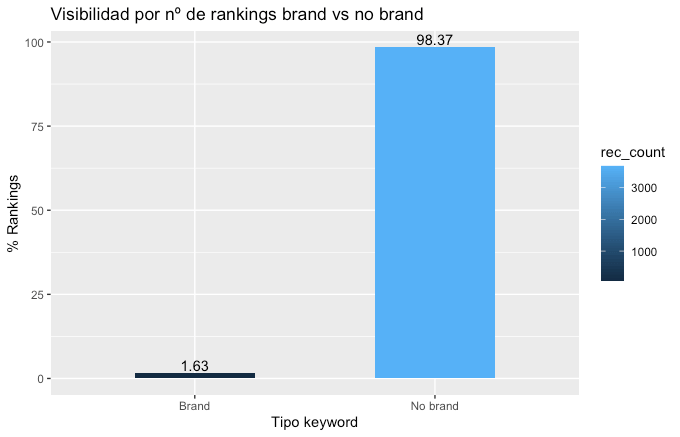
Y la visualización un poco más conseguida
plot_brand <- ggplot(data = brand, aes(reorder(brand, rec_count), y = per, label = round(per, digits = 2)))+
geom_col(aes(fill = per), show.legend = T)+
coord_flip()+
theme_bw()+
theme(axis.text = element_text(size = 12), axis.title = element_text(size = 14, colour = "black"))+
geom_label(aes(fill = per),
colour = "white",
fontface = "bold",
size = 4,
position = position_stack(0.8))+
labs(title = "Visibilidad por nº de rankings brand vs no brand",
subtitle = "Top 100 mobile",
x = "Tipo Keyword",
y = "% Rankings",
caption = '@mjcachon')
plot_brand
grid::grid.raster(logo, x = 0.07, y = 0.03, just = c('left', 'bottom'), width = unit(1, 'inches'))
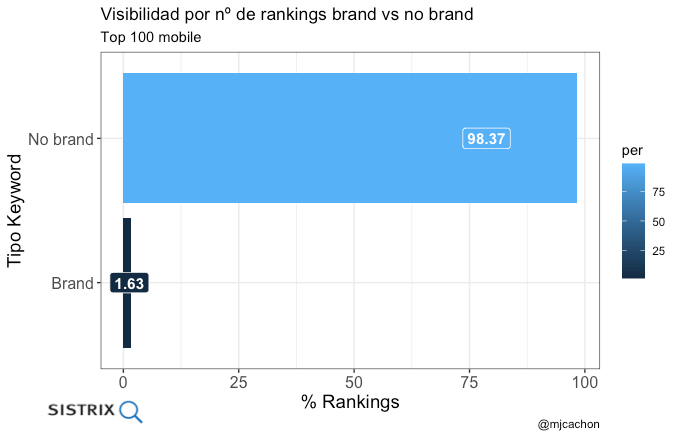
- Distribución de rankings por tipo de visibilidad
Usando la misma lógica con dplyr y ggplot2, se pueden crear tantas agrupaciones y visualizaciones como los datos permitan ser estrujados

- Distribución de rankings por página de Google
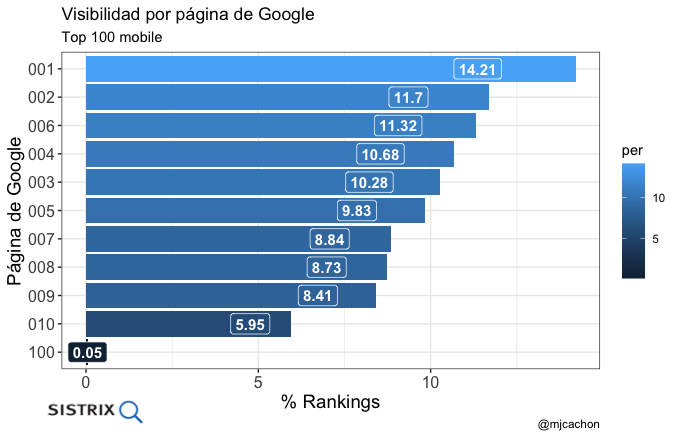
- Distribución de rankings por intent de la keyword
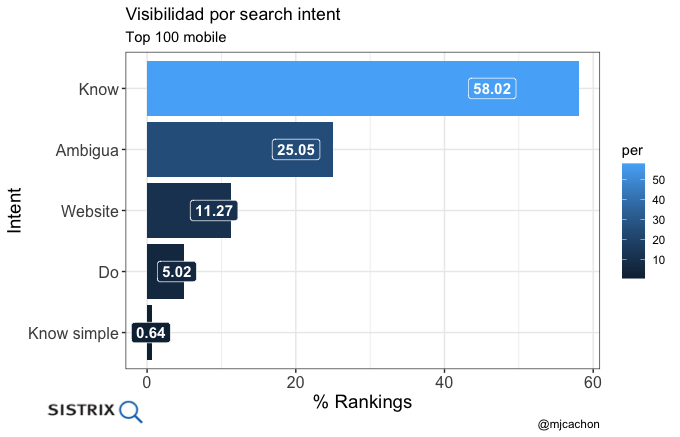
Se puede conseguir replicar el mismo código para construir otras agrupaciones como Distribución de rankings por path, Distribución de rankings por tipo de keyword, Distribución de rankings por volumen, etc.
Agrupar datos y pintarlos: usando dos criterios
Para agrupar 2 criteros en vez de 1, he usado también librerías adicionales y aquí ya entra en juego la paleta de colores que llamamos excel
install.packages("scales")
install.packages("hrbrthemes")
library(scales)
library(hrbrthemes)
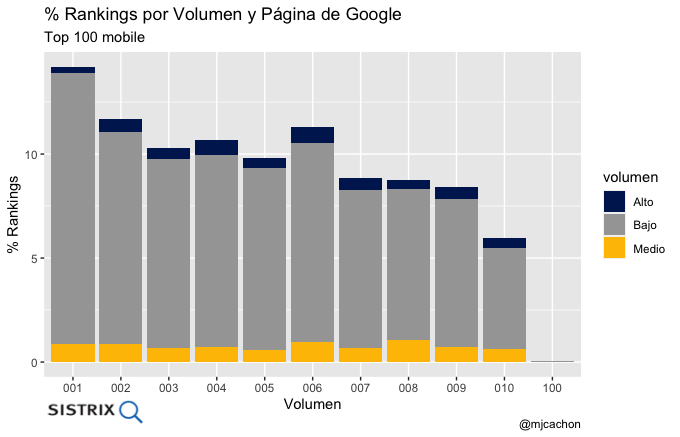
- Distribución de rankings por página de Google y volumen
pagina_google_volumen <- datos %>% group_by(pagina_google, volumen) %>% dplyr::summarise(rec_count = n()) %>% dplyr::mutate(per=rec_count/nrow(datos)*100.0) %>% dplyr::arrange(desc(rec_count))
gra_pagina_google_volumen <- ggplot(pagina_google_volumen, aes(fill=volumen, y=per, x=pagina_google)) +
geom_line(color="blue")+ labs(title = "% Rankings por Volumen y Página de Google",
subtitle = "Top 100 mobile",
x = "Volumen",
y = "% Rankings",
caption = '@mjcachon')+
geom_bar(position="stack", stat="identity")+
scale_fill_manual(values=excel)
gra_pagina_google_volumen
grid::grid.raster(logo, x = 0.07, y = 0.03, just = c('left', 'bottom'), width = unit(1, 'inches'))
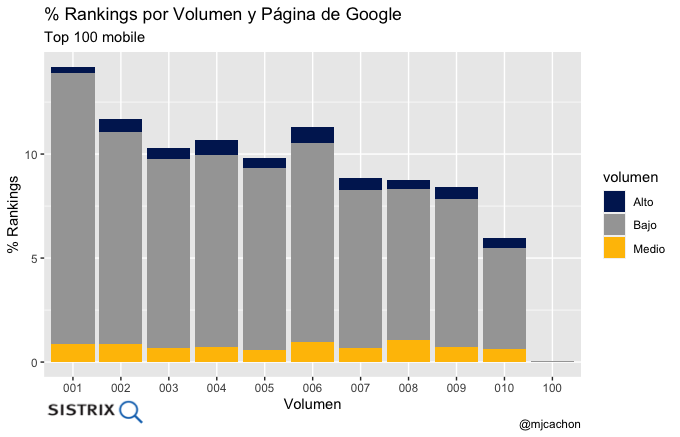
- Distribución de rankings por página de Google y search intent
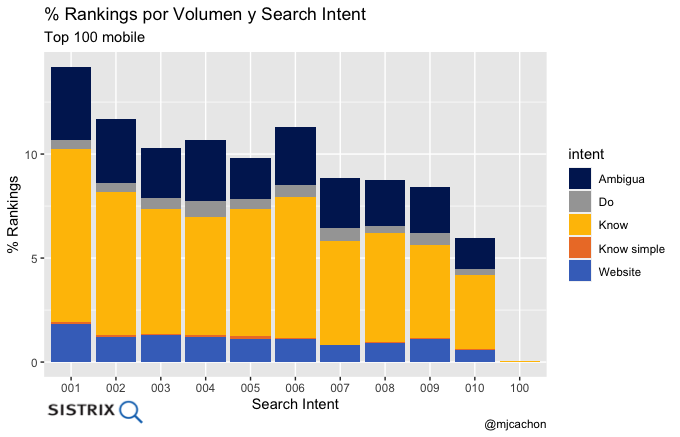
Podéis hacer mismas agrupaciones y gráficos para otros criterios como Distribución de rankings por página de Google y rankings marca o no marca, Distribución de rankings por página de Google y longitud de la palabra, etc.
Descargar gráficos
Para descargar los gráficos a vuestro directorio de trabajo, tan solo tenéis que llamar al gráfico y ponerle nombre al fichero que se descargará:
ggsave("gra_brand.png", plot = gra_brand)
ggsave("gra_google_brand.png", plot = gra_google_brand)
ggsave("gra_google_intent.png", plot = gra_google_intent)
ggsave("gra_google_tail.png", plot = gra_google_tail)
ggsave("gra_intent.png", plot = gra_intent)
Como veis, cualquier operación que hacemos en Excel o Sheets a diario, es susceptible de ser convertida en un script de R que nos da la oportunidad de automatizar ciertos procesos de forma muy rápida, ya no solo ejecutando línea a línea o ejecutando todo el código de golpe, sino también usando funcionalidades que permita crear programación de estas ejecuciones con la periodicidad que queramos (como por ejemplo lo que explican aquí)
¡Esto es todo por hoy y espero que os haya sido útil!
Soy MJ Cachón
Consultora SEO desde 2008, directora de la agencia SEO Laika. Volcada en unir el análisis de datos y el SEO estratégico, con business intelligence usando R, Screaming Frog, SISTRIX, Sitebulb y otras fuentes de datos. Mi filosofía: aprender y compartir.